| .. | ||
| humaneval | ||
| codet5p_architecture.png | ||
| codet5p_overview.png | ||
| deepspeed_config.json | ||
| instruct_tune_codet5p.py | ||
| README.md | ||
| tune_codet5p_seq2seq.py | ||
{kind=link}
{kind=link}
CodeT5+
Official research release for the CodeT5+ models (220M, 770M, 2B, 6B 16B) for a wide range of Code Understanding and Generation tasks.
Find out more via our blog post.
Title: CodeT5+: Open Code Large Language Models for Code Understanding and Generation
Authors: Yue Wang*, Hung Le*, Akhilesh Deepak Gotmare, Nghi D.Q. Bui, Junnan Li, Steven C.H. Hoi (* indicates equal contribution)
What is this about?
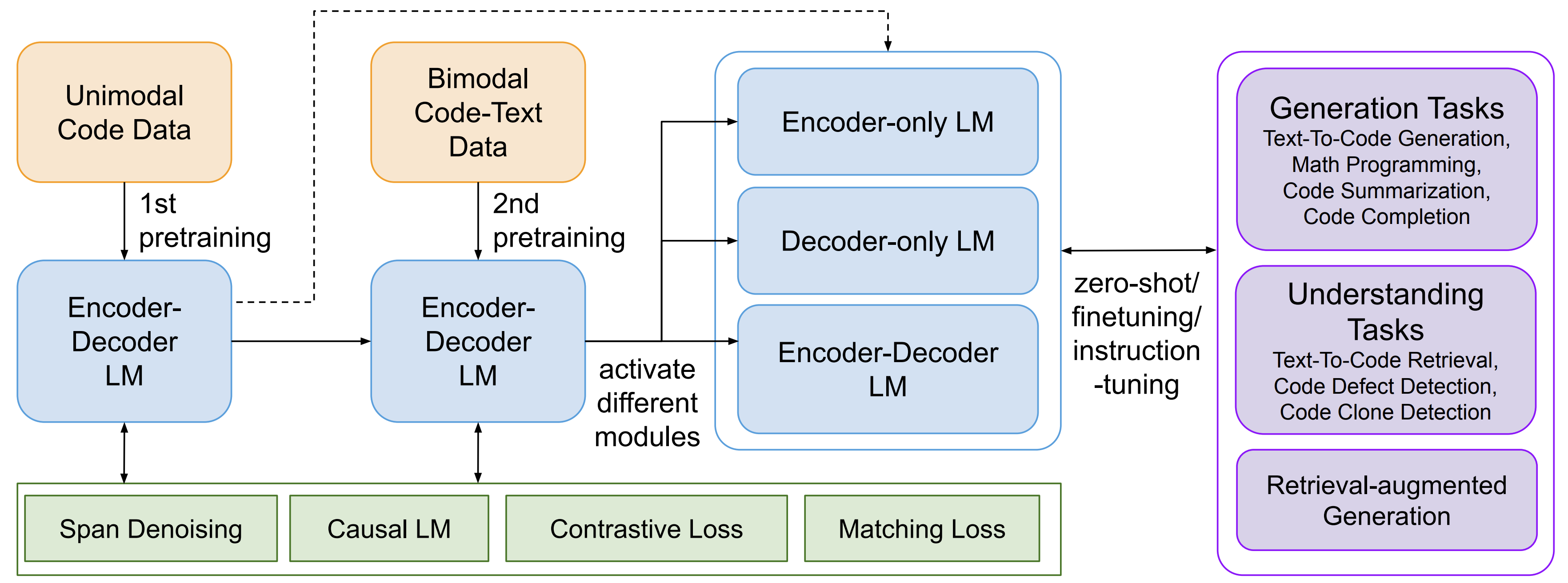
CodeT5+ is a new family of open code large language models with an encoder-decoder architecture that can flexibly operate in different modes (i.e. encoder-only, decoder-only, and encoder-decoder) to support a wide range of code understanding and generation tasks.
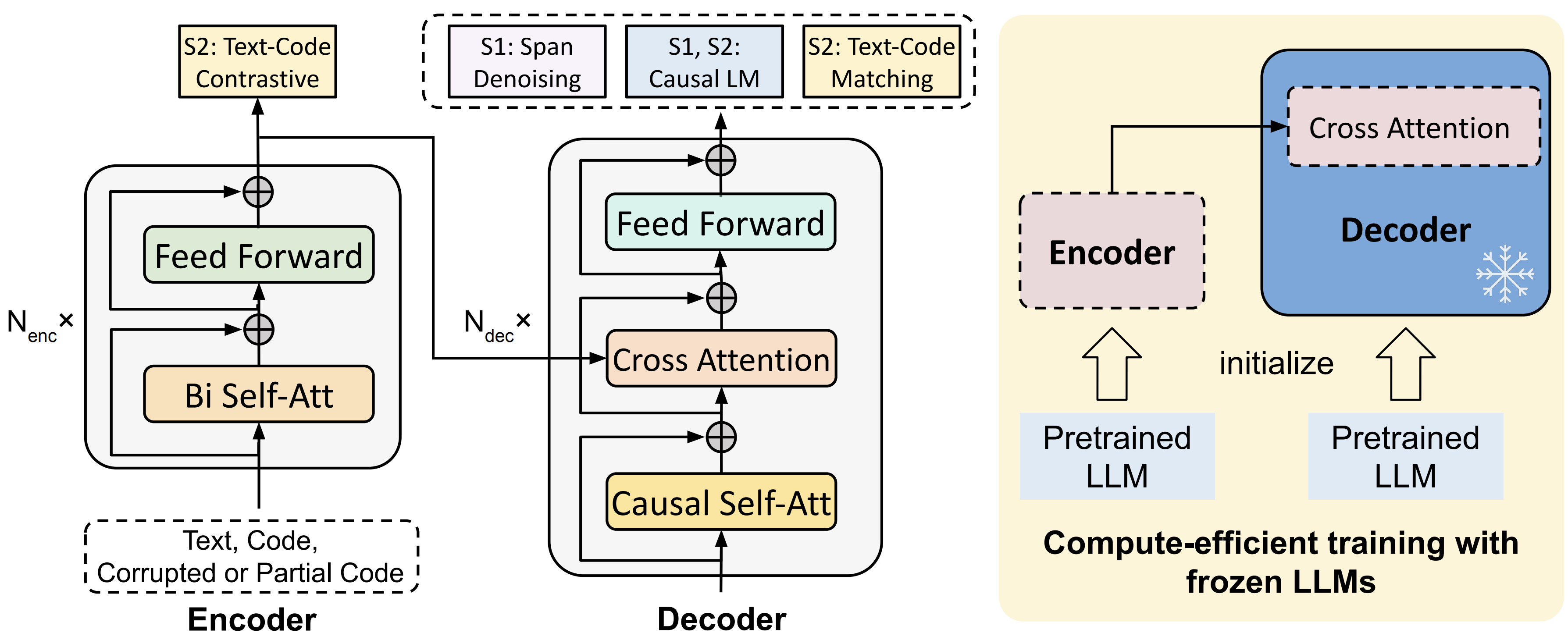
To train CodeT5+, we introduce a diverse set of pretraining tasks including span denoising, causal language modeling, contrastive learning, and text-code matching to learn rich representations from both unimodal code data and bimodal code-text data. Additionally, to efficiently scale up the model, we propose a simple yet effective compute-efficient pretraining method to initialize our model with frozen off-the-shelf LLMs such as CodeGen. Furthermore, we explore instruction tuning to align the model with natural language instructions following Code Alpaca. See the below overview of CodeT5+.
Released Models
We implemented a family of CodeT5+ models, with model size ranging from 220M to 16B.
Note that CodeT5+ 220M and 770M employ the same architecture of CodeT5-base and large respectively and are pretrained from scratch, while CodeT5+ 2B, 6B, 16B employ a "shallow encoder and deep decoder" architecture with the shallow encoder initialized from CodeGen-mono 350M and the deep decoder initialized from CodeGen-mono 2B, 6B, 16B, respectively.
InstructCodeT5+ 16B is our instruction-tuned model from CodeT5+ 16B.
Note that as this model utilizes instruction tuning data curated using OpenAI API, the checkpoint of InstructCodeT5+ 16B is licensed for research and non-commercial use only.
We release the following CodeT5+ models at Huggingface:
- CodeT5+
220Mand770M: codet5p-220m and codet5p-770m. - CodeT5+
220Mand770Mthat are further tuned on Python subset: codet5p-220m-py and codet5p-770m-py. - CodeT5+
2B,6B,16B: codet5p-2b, codet5p-6b, and codet5p-16b. - InstructCodeT5+
16B: instructcodet5p-16b.
How to Use?
All CodeT5+ models and tokenizers can be easily loaded using the AutoModelForSeq2SeqLM and AutoTokenizer functionality.
For tokenizers, CodeT5+ 220M and 770M employ the same tokenizer as the original CodeT5 while CodeT5+ 2B, 6B, 16B employ the same tokenizer as CodeGen.
For CodeT5+ 2B, 6B, 16B, and InstructCodeT5+ 16B, please set trust_remote_code=True when loading the models as the model class is defined in the Huggingface repo.
Besides, these models would benefit from passing additional prompts to the decoder via decoder_input_ids to achieve better generation performance.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
checkpoint = "Salesforce/instructcodet5p-16b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Instruction Tuning to Align with Natural Language Instructions
We explore instruction tuning to align CodeT5+ with natural language instructions following Code Alpaca. First download the instruction data code_alpaca_20k.json from here.
Then, you can run the following command to finetune CodeT5+ 16B on the instruction data.
MODEL=Salesforce/codet5p-16b
SAVE_DIR=saved_models/instructcodet5p-16b
deepspeed instruct_tune_codet5p.py \
--load $MODEL --save-dir $SAVE_DIR --instruct-data-path code_alpaca_20k.json \
--fp16 --deepspeed deepspeed_config.json
How to Finetune Using Your Own Data?
We provide an example finetuning script tune_codet5p_seq2seq.py for CodeT5+ models on Seq2Seq LM task.
After installing the transformers and datasets libraries, you can run python tune_codet5p_seq2seq.py to finetune CodeT5+ models on any Seq2Seq LM tasks such as Python code summarization as illustrated in the script.
To finetune on your own data, you just need to prepare your customized data in the datasets format and pass its path to --cache-data.
Besides, you can specify --load to select the specific CodeT5+ model (e.g., Salesforce/codet5p-220m) to finetune from. To tune the hyper-parameter setting that suit your task the best, you can customize other finetuning arguments such as --epochs, --lr, --lr-warmup-steps, --max-source-len, --max-target-len, --batch-size-per-replica, --grad-acc-steps, etc.
This script naturally supports both single-GPU and multi-GPU training. If you have limited GPU memory issue and want to improve the training throughput, please consider to specify --fp16 to enable mixed-precision training and use DeepSpeed for further optimization by passing a deedspeed config file to --deepspeed (see here for an example config file).
Reproduce the Results
HumanEval
Installation
- Install the official HumanEval evaluation tool released by OpenAI following the instructions in this repo.
- Install the Pytorch (version
1.13.1) and transformers (version4.21.3) libraries.
Generating programs from CodeT5+ models
cd humaneval then run the inference via bash run_generate.sh.
You can select the model to generate from by changing the model variable in the script.
Following the original setting in the HumanEval paper, we generate 200 programs (pred_num=200) for each problem and employs nucleus sampling with different temperature T for computing pass@k (T=0.2,0.6,0.8 for k=1,10,100 respectively).
The generated programs will be saved in preds/${model}_T${T}_N${pred_num}.
model=instructcodet5p-16b
temp=0.2
max_len=800
pred_num=200
num_seqs_per_iter=2 # 25 for 350M and 770M, 10 for 2B, 8 for 6B, 2 for 16B on A100-40G
output_path=preds/${model}_T${temp}_N${pred_num}
mkdir -p ${output_path}
echo 'Output path: '$output_path
echo 'Model to eval: '$model
# 164 problems, 21 per GPU if GPU=8
index=0
gpu_num=8
for ((i = 0; i < $gpu_num; i++)); do
start_index=$((i * 21))
end_index=$(((i + 1) * 21))
gpu=$((i))
echo 'Running process #' ${i} 'from' $start_index 'to' $end_index 'on GPU' ${gpu}
((index++))
(
CUDA_VISIBLE_DEVICES=$gpu python generate_codet5p.py --model Salesforce/${model} \
--start_index ${start_index} --end_index ${end_index} --temperature ${temp} \
--num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path}
) &
if (($index % $gpu_num == 0)); then wait; fi
done
Evaluating pass@k
cd humaneval then run the evaluation via bash run_eval.sh.
output_path=preds/instructcodet5p-16b_T0.2_N200
echo 'Output path: '$output_path
python process_preds.py --path ${output_path} --out_path ${output_path}.jsonl
evaluate_functional_correctness ${output_path}.jsonl
We also released the model predictions for our InstructCodeT5+ 16B at humaneval/instructcodet5p-16b_T0.2_N200.jsonl for your reference.
It can reproduce the results of 36.1% Pass@1 with the following command. Note that this result is slightly different from the reported 35.0% Pass@1 in the paper due to the randomness of the sampling process.
evaluate_functional_correctness humaneval/instructcodet5p-16b_T0.2_N200.jsonl
Citation
@article{wang2023codet5plus,
title={CodeT5+: Open Code Large Language Models for Code Understanding and Generation},
author={Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi D.Q. and Li, Junnan and Hoi, Steven C. H.},
journal={arXiv preprint},
year={2023}
}