17 KiB
Adversarial ML Threat Matrix
Structure of Adversarial ML Threat Matrix
Because the Adversarial ML Threat Matrix is fashioned after ATT&CK Enterprise, it retains the terminologies: for instance, the column heads of the Threat Matrix are called "Tactics" and the individual entities are called "Techniques".
However, there are two main differences:
-
ATT&CK Enterprise is generally designed for corporate network which is composed of many sub components like workstation, bastion hosts, database, network gear, active directory, cloud component and so on. The tactics of ATT&CK enterprise (initial access, persistence, etc) are really a short hand of saying initial access to corporate network; persistence in corporate network. In Adversarial ML Threat Matrix, we acknowledge that ML systems are part of corporate network but wanted to highlight the uniqueness of the attacks.
Difference: In the Adversarial ML Threat Matrix, the "Tactics" should be read as "reconnaissance of ML subsystem", "persistence in ML subsystem", "evading the ML subsystem"
-
When we analyzed real-world attacks on ML systems, we found out that attackers can pursue different strategies: Rely on traditional cybersecurity technique only; Rely on Adversarial ML techniques only; or Employ a combination of traditional cybersecurity techniques and ML techniques.
Difference: In Adversarial ML Threat Matrix, "Techniques" come in two flavors:
-
Techniques in orange are specific to ML systems
-
Techniques in white are applicable to both ML and non-ML systems and come directly from Enterprise ATT&CK
Note: The Adversarial ML Threat Matrix is not yet part of the ATT&CK matrix.
-
Things to keep in mind before you use the framework:
- This is a first cut attempt at collating known adversary techniques against ML Systems. We plan to iterate on the framework based on feedback from the security and adversarial machine learning community (please engage with us and help make the matrix better!). Net-Net: This is a living document that will be routinely updated.
- Have feedback or improvements? We want in! See Feedback
- Only known bad is listed in the Matrix. Adversarial ML is an active area of research with new classes constantly being discovered. If you find a technique that is not listed, please enlist it in the framework (see section on Feedback)
- We are not prescribing definitive defenses at this point - The world of adversarial. We are already in conversations to add best practices in future revisions such as adversarial training for adversarial examples, restricting the number of significant digits in confidence score for model stealing.
- This is not a risk prioritization framework - The Threat Matrix only collates the known techniques; it does not provide a means to prioritize the risks.
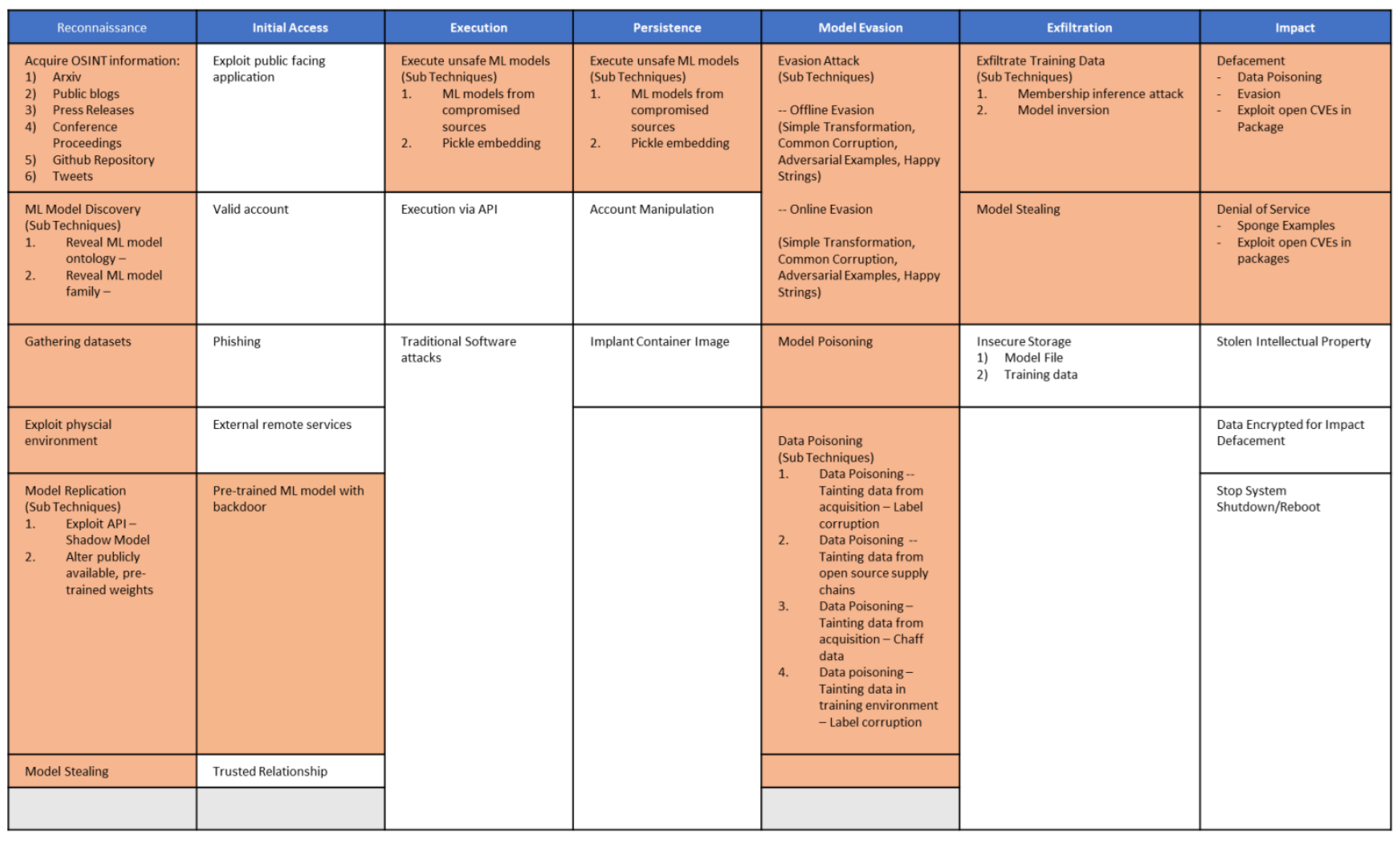
Adversarial ML Matrix - Description
Reconnaissance
Dataset Collection
Adversaries may collect datasets similar to those used by a particular organization or in a specific approach. Datasets may be identified during Public Information Acquisition. This may allow the adversary to replicate a private model's funcionality, constituting Intellectual Property Theft, or enable the adversary to carry out other attacks such as ML Model Evasion.
Acquire OSINT Information
Adversaries may leverage publicly available information about an organization that could identify where or how machine learning is being used in a system, and help tailor an attack to make it more effective. These sources of information include technical publications, blog posts, press releases, software repositories, public data repositories, and social media postings.
ML Model Discovery
Adversaries may attempt to identify machine learning pipelines that exist on the system and gather information about them, including the software stack used to train and deploy models, training and testing data repositories, model repositories, and software repositories containing algorithms. This information can be used to identify targets for further collection, exfiltration, or disruption, or to tailor and improve attacks. Once this information is identified, data may be collected during ML Pipeline Collection.
Initial Access
Pre-trained ML Model with Backdoor
Adversaries may gain initial access to a system by compromising portions of the ML supply chain. This could include GPU hardware, data and its annotations, parts of the ML software stack, or the model itself. In some instances the attacker will need secondary access to fully carry out an attack using compromised components of the supply chain.
Exploit Public-Facing Application
Adversaries may attempt to take advantage of a weakness in an Internet-facing computer or program using software, data, or commands in order to cause unintended or unanticipated behavior. The weakness in the system can be a bug, a glitch, or a design vulnerability. These applications are often websites, but can include databases (like SQL)(Citation: NVD CVE-2016-6662), standard services (like SMB(Citation: CIS Multiple SMB Vulnerabilities) or SSH), and any other applications with Internet accessible open sockets, such as web servers and related services.(Citation: NVD CVE-2014-7169) Depending on the flaw being exploited this may include Exploitation for Defense Evasion.
If an application is hosted on cloud-based infrastructure, then exploiting it may lead to compromise of the underlying instance. This can allow an adversary a path to access the cloud APIs or to take advantage of weak identity and access management policies.
For websites and databases, the OWASP top 10 and CWE top 25 highlight the most common web-based vulnerabilities.(Citation: OWASP Top 10)(Citation: CWE top 25)
Phishing
Adversaries may send phishing messages to elicit sensitive information and/or gain access to victim systems. All forms of phishing are electronically delivered social engineering. Phishing can be targeted, known as spearphishing. In spearphishing, a specific individual, company, or industry will be targeted by the adversary. More generally, adversaries can conduct non-targeted phishing, such as in mass malware spam campaigns.
Adversaries may send victim’s emails containing malicious attachments or links, typically to execute malicious code on victim systems or to gather credentials for use of Valid Accounts. Phishing may also be conducted via third-party services, like social media platforms.
Trusted Relationship
Adversaries may breach or otherwise leverage organizations who have access to intended victims. Access through trusted third party relationship exploits an existing connection that may not be protected or receives less scrutiny than standard mechanisms of gaining access to a network.
Organizations often grant elevated access to second or third-party external providers in order to allow them to manage internal systems as well as cloud-based environments. Some examples of these relationships include IT services contractors, managed security providers, infrastructure contractors (e.g. HVAC, elevators, physical security). The third-party provider's access may be intended to be limited to the infrastructure being maintained, but may exist on the same network as the rest of the enterprise. As such, Valid Accounts used by the other party for access to internal network systems may be compromised and used.
Valid Accounts
Adversaries may obtain and abuse credentials of existing accounts as a means of gaining Initial Access, Persistence, Privilege Escalation, or Defense Evasion. Compromised credentials may be used to bypass access controls placed on various resources on systems within the network and may even be used for persistent access to remote systems and externally available services, such as VPNs, Outlook Web Access and remote desktop. Compromised credentials may also grant an adversary increased privilege to specific systems or access to restricted areas of the network. Adversaries may choose not to use malware or tools in conjunction with the legitimate access those credentials provide to make it harder to detect their presence.
The overlap of permissions for local, domain, and cloud accounts across a network of systems is of concern because the adversary may be able to pivot across accounts and systems to reach a high level of access (i.e., domain or enterprise administrator) to bypass access controls set within the enterprise. (Citation: TechNet Credential Theft)
Execution
Unsafe ML Model Execution
An Adversary may utilize unsafe ML Models that when executed have an unintended effect. The adversary can use this technique to establish persistent access to systems. These models may be introduced via a compromised ML supply chain. An example of this technique is to use pickle embedding to introduce malicious data payloads.
Persistence
Unsafe ML Model Execution
An Adversary may utilize unsafe ML Models that when executed have an unintended effect. The adversary can use this technique to establish persistent access to systems. These models may be introduced via a compromised ML supply chain. An example of this technique is to use pickle embedding to introduce malicious data payloads.
Account Manipulation
Adversaries may manipulate accounts to maintain access to victim systems. Account manipulation may consist of any action that preserves adversary access to a compromised account, such as modifying credentials or permission groups. These actions could also include account activity designed to subvert security policies, such as performing iterative password updates to bypass password duration policies and preserve the life of compromised credentials. In order to create or manipulate accounts, the adversary must already have sufficient permissions on systems or the domain.
Implant Container Image
Adversaries may implant cloud container images with malicious code to establish persistence. Amazon Web Service (AWS) Amazon Machine Images (AMI), Google Cloud Platform (GCP) Images, and Azure Images as well as popular container runtimes such as Docker can be implanted or backdoored. Depending on how the infrastructure is provisioned, this could provide persistent access if the infrastructure provisioning tool is instructed to always use the latest image.(Citation: Rhino Labs Cloud Image Backdoor Technique Sept 2019)
A tool has been developed to facilitate planting backdoors in cloud container images.(Citation: Rhino Labs Cloud Backdoor September 2019) If an attacker has access to a compromised AWS instance, and permissions to list the available container images, they may implant a backdoor such as a Web Shell.(Citation: Rhino Labs Cloud Image Backdoor Technique Sept 2019) Adversaries may also implant Docker images that may be inadvertently used in cloud deployments, which has been reported in some instances of cryptomining botnets.(Citation: ATT Cybersecurity Cryptocurrency Attacks on Cloud)
Defense Evasion
Evasion Attack
Adversaries can create data inputs that prevent a machine learning model from positively identifying the data sample. This technique can be used to evade detection on the network, or to evade a downstream task where machine learning is utilized.
Example evasion attacks include Simple Transformation, Common Corruption, Adversarial Examples, Happy String
Model Poisoning
Adversaries can train machine learning that are performant, but contain backdoors that produce inference errors when presented with input containing a trigger defined by the adversary. A model with a backdoor can be introduced by an innocent user via ML Supply Chain Compromise or can be a result of Data Poisoning. This backdoored model can be exploited at inference time with an Attack on ML model integrity
Data Poisoning
Adversaries may attempt to poison datasets used by a ML system by modifying the underlying data or its labels. This allows the adversary to embed vulnerabilities in ML models trained on the data that may not be easily detectable. The embedded vulnerability can be activated at a later time by providing the model with data containing the trigger. Data Poisoning can help enable attacks such as ML Model Evasion and ML Model Integrity Attacks.
Tainting Data from Acquisition - Label Corruption
Adversaries may attempt to alter labels in a training set. This would cause a model to misclassify an input
Tainting Data from Open Source Supply Chains
Adversaries may attempt to add their own data to an open source dataset which could create a classfication backdoor.
Tainting Data from Acquisition - Chaff Data
Adding noise to a dataset would lower the accuracy of the model, potentially making the model more vulnerable to misclassifications
Tainting Data in Training - Label Corruption
Changing training labels could create a backdoor in the model, such that a malicious input would always be classified to the benefit of the adversary
Exfiltration
Insecure Storage
Adversaries may exfiltrate proprietary machine learning models or private training and testing data by exploiting insecure storage mechanisms. Adversaries may discover, collect, and finally exfiltrate components of a ML pipeline, resulting in Intellectual Property Theft
Exfiltration Over ML Inference API
Adversaries may exfiltrate private information related to machine learning models via their inference APIs. Additionally, adversaries can use these APIs to create copy-cat or proxy models.
ML Model Inversion
Machine learning models' training data could be reconstructed by exploiting an inference API.
Training Data Membership Inference
The membership of a data sample in a training set may be infered by an adversary with access to an inference API.
ML Model Stealing
Machine learning models' functionality can be stolen exploiting an inference API. IP Theft.
Impact
ML Model Integrity Attacks
Adversaries may attack the integrity of machine learning models by crafting adversarial examples that appear to be normal inputs, but cause the model to make errors at inference time. These attacks can reduce prediction confidence and cause false positives or false negatives, eroding confidence in the system over time.
Evasion Attack
Adversaries can create data inputs that prevent a machine learning model from positively identifying the data sample. This technique can be used to evade detection on the network, or to evade a downstream task where machine learning is utilized.
Example evasion attacks include Simple Transformation, Common Corruption, Adversarial Examples, Happy String
Stolen Intellectual Property
Adversaries may steal intellectual property by replicating the functionality of ML models, or by exfiltrating private data over ML inference APIs.
Denial of Service
Adversaries may target different Machine Learning services to conduct a DoS.
One example of this type of attack is Sponge attack.
Data Encrypted for Impact
Adversaries may encrypt data on target systems or on large numbers of systems in a network to interrupt availability to system and network resources. They can attempt to render stored data inaccessible by encrypting files or data on local and remote drives and withholding access to a decryption key. This may be done in order to extract monetary compensation from a victim in exchange for decryption or a decryption key (ransomware) or to render data permanently inaccessible in cases where the key is not saved or transmitted.(Citation: US-CERT Ransomware 2016)(Citation: FireEye WannaCry 2017)(Citation: US-CERT NotPetya 2017)(Citation: US-CERT SamSam 2018) In the case of ransomware, it is typical that common user files like Office documents, PDFs, images, videos, audio, text, and source code files will be encrypted. In some cases, adversaries may encrypt critical system files, disk partitions, and the MBR.(Citation: US-CERT NotPetya 2017)
To maximize impact on the target organization, malware designed for encrypting data may have worm-like features to propagate across a network by leveraging other attack techniques like Valid Accounts, OS Credential Dumping, and SMB/Windows Admin Shares.(Citation: FireEye WannaCry 2017)(Citation: US-CERT NotPetya 2017)
Next Recommended Reading
See how the matrix can be used via Case Studies Page