* new skeleton Signed-off-by: Max Cembalest <max@nomic.ai> * v3 docs Signed-off-by: Max Cembalest <max@nomic.ai> --------- Signed-off-by: Max Cembalest <max@nomic.ai>
4.3 KiB
Models
GPT4All is optimized to run LLMs in the 3-13B parameter range on consumer-grade hardware.
LLMs are downloaded to your device so you can run them locally and privately. With our backend anyone can interact with LLMs efficiently and securely on their own hardware.
Download Models
!!! note "Download Models"
<div style="text-align: center; margin-top: 20px;">
<table style="margin-left: auto; margin-right: auto;">
<tr>
<td style="text-align: right; padding-right: 10px;">1.</td>
<td style="text-align: left;">Click `Models` in the menu on the left (below `Chats` and above `LocalDocs`)</td>
<td><img src="../assets/models_page_icon.png" alt="Models Page Icon" style="width: 80px; height: auto;"></td>
</tr>
<tr>
<td style="text-align: right; padding-right: 10px;">2.</td>
<td style="text-align: left;">Click `+ Add Model` to navigate to the `Explore Models` page</td>
<td><img src="../assets/add.png" alt="Add Model button" style="width: 100px; height: auto;"></td>
</tr>
<tr>
<td style="text-align: right; padding-right: 10px;">3.</td>
<td style="text-align: left;">Search for models available online</td>
<td><img src="../assets/explore.png" alt="Explore Models search" style="width: 120px; height: auto;"></td>
</tr>
<tr>
<td style="text-align: right; padding-right: 10px;">4.</td>
<td style="text-align: left;">Hit `Download` to save a model to your device</td>
<td><img src="../assets/download.png" alt="Download Models button" style="width: 120px; height: auto;"></td>
</tr>
<tr>
<td style="text-align: right; padding-right: 10px;">5.</td>
<td style="text-align: left;">Once the model is downloaded you will see it in `Models`.</td>
<td><img src="../assets/installed_models.png" alt="Download Models button" style="width: 120px; height: auto;"></td>
</tr>
</table>
</div>
Explore Models
GPT4All connects you with LLMs from HuggingFace with a llama.cpp backend so that they will run efficiently on your hardware. Many of these models can be identified by the file type .gguf.
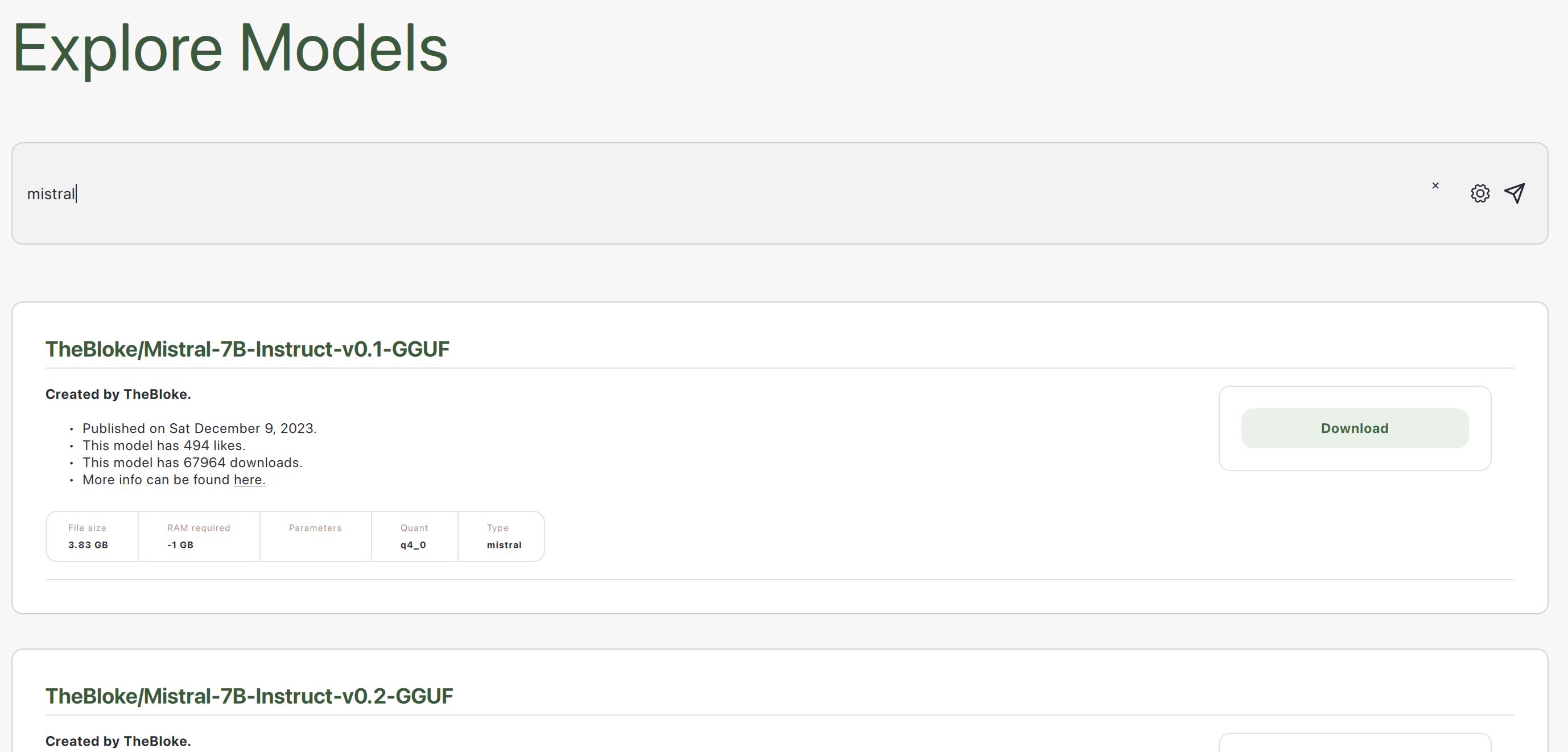
Example Models
Many LLMs are available at various sizes, quantizations, and licenses.
-
LLMs with more parameters tend to be better at coherently responding to instructions
-
LLMs with a smaller quantization (e.g. 4bit instead of 16bit) are much faster and less memory intensive, and tend to have slightly worse performance
-
Licenses vary in their terms for personal and commercial use
Here are a few examples:
| Model | Filesize | RAM Required | Parameters | Developer | License | MD5 Sum (Unique Hash) |
|---|---|---|---|---|---|---|
| Llama 3 Instruct | 4.66 GB | 8 GB | 8 Billion | Meta | Llama 3 License | c87ad09e1e4c8f9c35a5fcef52b6f1c9 |
| Nous Hermes 2 Mistral DPO | 4.21 GB | 8 GB | 7 Billion | Mistral & Nous Research | Apache 2.0 | Coa5f6b4eabd3992da4d7fb7f020f921eb |
| Phi-3 Mini Instruct | 2.03 GB | 4 GB | 4 billion | Microsoft | MIT | f8347badde9bfc2efbe89124d78ddaf5 |
| Mini Orca (Small) | 1.84 GB | 4 GB | 3 billion | Microsoft | CC-BY-NC-SA-4.0 | 0e769317b90ac30d6e09486d61fefa26 |
| GPT4All Snoozy | 7.36 GB | 16 GB | 13 billion | Nomic AI | GPL | 40388eb2f8d16bb5d08c96fdfaac6b2c |
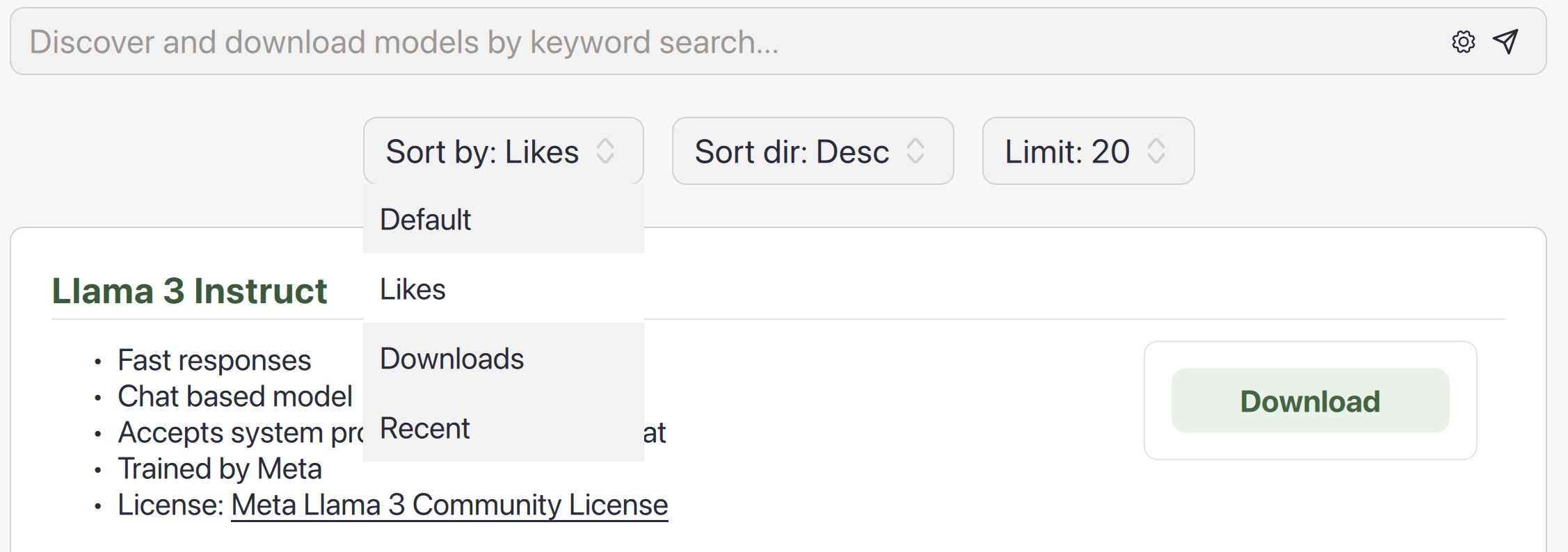
Search Results
You can click the gear icon in the search bar to sort search results by their # of likes, # of downloads, or date of upload (all from HuggingFace).
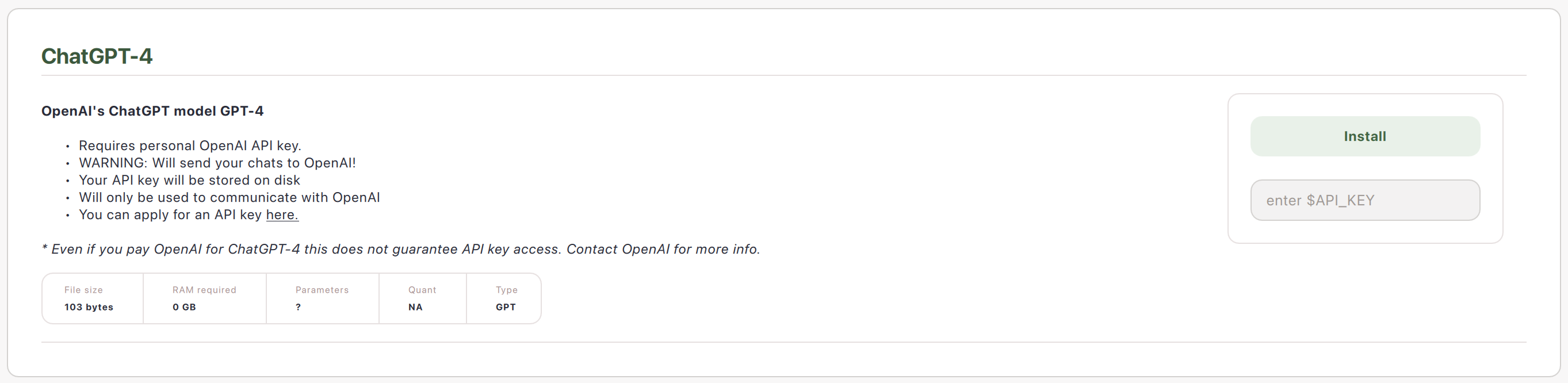
Connect Model APIs
You can add your API key for remote model providers.
Note: this does not download a model file to your computer to use securely. Instead, this way of interacting with models has your prompts leave your computer to the API provider and returns the response to your computer.