mirror of
https://mau.dev/maunium/synapse.git
synced 2024-10-01 01:36:05 -04:00
Port wiki pages to documentation website (#11402)
* move wiki pages to synapse/docs and add a few titles where necessary * update SUMMARY.md with added pages * add changelog * move incorrectly located newsfragment * update changelog number * snake case added files and update summary.md accordingly * update issue/pr links * update relative links to docs * update changelog to indicate that we moved wiki pages to the docs and state reasoning * revert unintentional change to CHANGES.md * add link Co-authored-by: Andrew Morgan <1342360+anoadragon453@users.noreply.github.com> * Update CHANGES.md Co-authored-by: Andrew Morgan <1342360+anoadragon453@users.noreply.github.com> Co-authored-by: Andrew Morgan <1342360+anoadragon453@users.noreply.github.com>
This commit is contained in:
parent
ed635d3285
commit
84dc50e160
17
CHANGES.md
17
CHANGES.md
@ -1,3 +1,19 @@
|
||||
UNRELEASED
|
||||
==========
|
||||
|
||||
We've decided to move the existing, somewhat stagnant pages from the GitHub wiki
|
||||
to the [documentation website](https://matrix-org.github.io/synapse/latest/).
|
||||
This was done for two reasons. The first was to ensure that changes are checked by
|
||||
multiple authors before being committed (everyone makes mistakes!) and the second
|
||||
was visibility of the documentation. Not everyone knows that Synapse has some very
|
||||
useful information hidden away in its GitHub wiki pages. Bringing them to the
|
||||
documentation website should help with visibility, as well as keep all Synapse documentation
|
||||
in one, easily-searchable location.
|
||||
|
||||
Note that contributions to the documentation website happen through [GitHub pull
|
||||
requests](https://github.com/matrix-org/synapse/pulls). Please visit [#synapse-dev:matrix.org](https://matrix.to/#/#synapse-dev:matrix.org)
|
||||
if you need help with the process!
|
||||
|
||||
Synapse 1.48.0 (2021-11-30)
|
||||
===========================
|
||||
|
||||
@ -86,6 +102,7 @@ Internal Changes
|
||||
- Refactor including the bundled relations when serializing an event. ([\#11408](https://github.com/matrix-org/synapse/issues/11408))
|
||||
|
||||
|
||||
|
||||
Synapse 1.47.1 (2021-11-23)
|
||||
===========================
|
||||
|
||||
|
||||
1
changelog.d/11402.misc
Normal file
1
changelog.d/11402.misc
Normal file
@ -0,0 +1 @@
|
||||
Add wiki pages to documentation website.
|
||||
@ -67,7 +67,12 @@
|
||||
- [Server Version](admin_api/version_api.md)
|
||||
- [Manhole](manhole.md)
|
||||
- [Monitoring](metrics-howto.md)
|
||||
- [Understanding Synapse Through Grafana Graphs](usage/administration/understanding_synapse_through_grafana_graphs.md)
|
||||
- [Useful SQL for Admins](usage/administration/useful_sql_for_admins.md)
|
||||
- [Database Maintenance Tools](usage/administration/database_maintenance_tools.md)
|
||||
- [State Groups](usage/administration/state_groups.md)
|
||||
- [Request log format](usage/administration/request_log.md)
|
||||
- [Admin FAQ](usage/administration/admin_faq.md)
|
||||
- [Scripts]()
|
||||
|
||||
# Development
|
||||
@ -95,3 +100,4 @@
|
||||
|
||||
# Other
|
||||
- [Dependency Deprecation Policy](deprecation_policy.md)
|
||||
- [Running Synapse on a Single-Board Computer](other/running_synapse_on_single_board_computers.md)
|
||||
|
||||
74
docs/other/running_synapse_on_single_board_computers.md
Normal file
74
docs/other/running_synapse_on_single_board_computers.md
Normal file
@ -0,0 +1,74 @@
|
||||
## Summary of performance impact of running on resource constrained devices such as SBCs
|
||||
|
||||
I've been running my homeserver on a cubietruck at home now for some time and am often replying to statements like "you need loads of ram to join large rooms" with "it works fine for me". I thought it might be useful to curate a summary of the issues you're likely to run into to help as a scaling-down guide, maybe highlight these for development work or end up as documentation. It seems that once you get up to about 4x1.5GHz arm64 4GiB these issues are no longer a problem.
|
||||
|
||||
- **Platform**: 2x1GHz armhf 2GiB ram [Single-board computers](https://wiki.debian.org/CheapServerBoxHardware), SSD, postgres.
|
||||
|
||||
### Presence
|
||||
|
||||
This is the main reason people have a poor matrix experience on resource constrained homeservers. Element web will frequently be saying the server is offline while the python process will be pegged at 100% cpu. This feature is used to tell when other users are active (have a client app in the foreground) and therefore more likely to respond, but requires a lot of network activity to maintain even when nobody is talking in a room.
|
||||
|
||||

|
||||
|
||||
While synapse does have some performance issues with presence [#3971](https://github.com/matrix-org/synapse/issues/3971), the fundamental problem is that this is an easy feature to implement for a centralised service at nearly no overhead, but federation makes it combinatorial [#8055](https://github.com/matrix-org/synapse/issues/8055). There is also a client-side config option which disables the UI and idle tracking [enable_presence_by_hs_url] to blacklist the largest instances but I didn't notice much difference, so I recommend disabling the feature entirely at the server level as well.
|
||||
|
||||
[enable_presence_by_hs_url]: https://github.com/vector-im/element-web/blob/v1.7.8/config.sample.json#L45
|
||||
|
||||
### Joining
|
||||
|
||||
Joining a "large", federated room will initially fail with the below message in Element web, but waiting a while (10-60mins) and trying again will succeed without any issue. What counts as "large" is not message history, user count, connections to homeservers or even a simple count of the state events, it is instead how long the state resolution algorithm takes. However, each of those numbers are reasonable proxies, so we can use them as estimates since user count is one of the few things you see before joining.
|
||||
|
||||

|
||||
|
||||
This is [#1211](https://github.com/matrix-org/synapse/issues/1211) and will also hopefully be mitigated by peeking [matrix-org/matrix-doc#2753](https://github.com/matrix-org/matrix-doc/pull/2753) so at least you don't need to wait for a join to complete before finding out if it's the kind of room you want. Note that you should first disable presence, otherwise it'll just make the situation worse [#3120](https://github.com/matrix-org/synapse/issues/3120). There is a lot of database interaction too, so make sure you've [migrated your data](../postgres.md) from the default sqlite to postgresql. Personally, I recommend patience - once the initial join is complete there's rarely any issues with actually interacting with the room, but if you like you can just block "large" rooms entirely.
|
||||
|
||||
### Sessions
|
||||
|
||||
Anything that requires modifying the device list [#7721](https://github.com/matrix-org/synapse/issues/7721) will take a while to propagate, again taking the client "Offline" until it's complete. This includes signing in and out, editing the public name and verifying e2ee. The main mitigation I recommend is to keep long-running sessions open e.g. by using Firefox SSB "Use this site in App mode" or Chromium PWA "Install Element".
|
||||
|
||||
### Recommended configuration
|
||||
|
||||
Put the below in a new file at /etc/matrix-synapse/conf.d/sbc.yaml to override the defaults in homeserver.yaml.
|
||||
|
||||
```
|
||||
# Set to false to disable presence tracking on this homeserver.
|
||||
use_presence: false
|
||||
|
||||
# When this is enabled, the room "complexity" will be checked before a user
|
||||
# joins a new remote room. If it is above the complexity limit, the server will
|
||||
# disallow joining, or will instantly leave.
|
||||
limit_remote_rooms:
|
||||
# Uncomment to enable room complexity checking.
|
||||
#enabled: true
|
||||
complexity: 3.0
|
||||
|
||||
# Database configuration
|
||||
database:
|
||||
name: psycopg2
|
||||
args:
|
||||
user: matrix-synapse
|
||||
# Generate a long, secure one with a password manager
|
||||
password: hunter2
|
||||
database: matrix-synapse
|
||||
host: localhost
|
||||
cp_min: 5
|
||||
cp_max: 10
|
||||
```
|
||||
|
||||
Currently the complexity is measured by [current_state_events / 500](https://github.com/matrix-org/synapse/blob/v1.20.1/synapse/storage/databases/main/events_worker.py#L986). You can find join times and your most complex rooms like this:
|
||||
|
||||
```
|
||||
admin@homeserver:~$ zgrep '/client/r0/join/' /var/log/matrix-synapse/homeserver.log* | awk '{print $18, $25}' | sort --human-numeric-sort
|
||||
29.922sec/-0.002sec /_matrix/client/r0/join/%23debian-fasttrack%3Apoddery.com
|
||||
182.088sec/0.003sec /_matrix/client/r0/join/%23decentralizedweb-general%3Amatrix.org
|
||||
911.625sec/-570.847sec /_matrix/client/r0/join/%23synapse%3Amatrix.org
|
||||
|
||||
admin@homeserver:~$ sudo --user postgres psql matrix-synapse --command 'select canonical_alias, joined_members, current_state_events from room_stats_state natural join room_stats_current where canonical_alias is not null order by current_state_events desc fetch first 5 rows only'
|
||||
canonical_alias | joined_members | current_state_events
|
||||
-------------------------------+----------------+----------------------
|
||||
#_oftc_#debian:matrix.org | 871 | 52355
|
||||
#matrix:matrix.org | 6379 | 10684
|
||||
#irc:matrix.org | 461 | 3751
|
||||
#decentralizedweb-general:matrix.org | 997 | 1509
|
||||
#whatsapp:maunium.net | 554 | 854
|
||||
```
|
||||
96
docs/usage/administration/admin_faq.md
Normal file
96
docs/usage/administration/admin_faq.md
Normal file
@ -0,0 +1,96 @@
|
||||
## Admin FAQ
|
||||
|
||||
How do I become a server admin?
|
||||
---
|
||||
If your server already has an admin account you should use the user admin API to promote other accounts to become admins. See [User Admin API](../../admin_api/user_admin_api.md#Change-whether-a-user-is-a-server-administrator-or-not)
|
||||
|
||||
If you don't have any admin accounts yet you won't be able to use the admin API so you'll have to edit the database manually. Manually editing the database is generally not recommended so once you have an admin account, use the admin APIs to make further changes.
|
||||
|
||||
UPDATE users SET admin = 1 WHERE name = '@foo:bar.com';
|
||||
|
||||
What servers are my server talking to?
|
||||
---
|
||||
Run this sql query on your db:
|
||||
|
||||
SELECT * FROM destinations;
|
||||
|
||||
What servers are currently participating in this room?
|
||||
---
|
||||
Run this sql query on your db:
|
||||
|
||||
SELECT DISTINCT split_part(state_key, ':', 2)
|
||||
FROM current_state_events AS c
|
||||
INNER JOIN room_memberships AS m USING (room_id, event_id)
|
||||
WHERE room_id = '!cURbafjkfsMDVwdRDQ:matrix.org' AND membership = 'join';
|
||||
|
||||
What users are registered on my server?
|
||||
---
|
||||
|
||||
SELECT NAME from users;
|
||||
|
||||
Manually resetting passwords:
|
||||
---
|
||||
See https://github.com/matrix-org/synapse/blob/master/README.rst#password-reset
|
||||
|
||||
I have a problem with my server. Can I just delete my database and start again?
|
||||
---
|
||||
Deleting your database is unlikely to make anything better.
|
||||
|
||||
It's easy to make the mistake of thinking that you can start again from a clean slate by dropping your database, but things don't work like that in a federated network: lots of other servers have information about your server.
|
||||
|
||||
For example: other servers might think that you are in a room, your server will think that you are not, and you'll probably be unable to interact with that room in a sensible way ever again.
|
||||
|
||||
In general, there are better solutions to any problem than dropping the database. Come and seek help in https://matrix.to/#/#synapse:matrix.org.
|
||||
|
||||
There are two exceptions when it might be sensible to delete your database and start again:
|
||||
* You have *never* joined any rooms which are federated with other servers. For instance, a local deployment which the outside world can't talk to.
|
||||
* You are changing the `server_name` in the homeserver configuration. In effect this makes your server a completely new one from the point of view of the network, so in this case it makes sense to start with a clean database.
|
||||
(In both cases you probably also want to clear out the media_store.)
|
||||
|
||||
I've stuffed up access to my room, how can I delete it to free up the alias?
|
||||
---
|
||||
Using the following curl command:
|
||||
|
||||
curl -H 'Authorization: Bearer <access-token>' -X DELETE https://matrix.org/_matrix/client/r0/directory/room/<room-alias>
|
||||
|
||||
\<access-token\> - can be obtained in riot by looking in the riot settings, down the bottom is:
|
||||
Access Token:\<click to reveal\>
|
||||
|
||||
\<room-alias\> - the room alias, eg. #my_room:matrix.org this possibly needs to be URL encoded also, for example %23my_room%3Amatrix.org
|
||||
|
||||
How can I find the lines corresponding to a given HTTP request in my homeserver log?
|
||||
---
|
||||
|
||||
Synapse tags each log line according to the HTTP request it is processing. When it finishes processing each request, it logs a line containing the words `Processed request: `. For example:
|
||||
|
||||
```
|
||||
2019-02-14 22:35:08,196 - synapse.access.http.8008 - 302 - INFO - GET-37 - ::1 - 8008 - {@richvdh:localhost} Processed request: 0.173sec/0.001sec (0.002sec, 0.000sec) (0.027sec/0.026sec/2) 687B 200 "GET /_matrix/client/r0/sync HTTP/1.1" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36" [0 dbevts]"
|
||||
```
|
||||
|
||||
Here we can see that the request has been tagged with `GET-37`. (The tag depends on the method of the HTTP request, so might start with `GET-`, `PUT-`, `POST-`, `OPTIONS-` or `DELETE-`.) So to find all lines corresponding to this request, we can do:
|
||||
|
||||
```
|
||||
grep 'GET-37' homeserver.log
|
||||
```
|
||||
|
||||
If you want to paste that output into a github issue or matrix room, please remember to surround it with triple-backticks (```) to make it legible (see https://help.github.com/en/articles/basic-writing-and-formatting-syntax#quoting-code).
|
||||
|
||||
|
||||
What do all those fields in the 'Processed' line mean?
|
||||
---
|
||||
See [Request log format](request_log.md).
|
||||
|
||||
|
||||
What are the biggest rooms on my server?
|
||||
---
|
||||
|
||||
```sql
|
||||
SELECT s.canonical_alias, g.room_id, count(*) AS num_rows
|
||||
FROM
|
||||
state_groups_state AS g,
|
||||
room_stats_state AS s
|
||||
WHERE g.room_id = s.room_id
|
||||
GROUP BY s.canonical_alias, g.room_id
|
||||
ORDER BY num_rows desc
|
||||
LIMIT 10;
|
||||
```
|
||||
36
docs/usage/administration/database_maintenance_tools.md
Normal file
36
docs/usage/administration/database_maintenance_tools.md
Normal file
@ -0,0 +1,36 @@
|
||||
This blog post by Victor Berger explains how to use many of the tools listed on this page: https://levans.fr/shrink-synapse-database.html
|
||||
|
||||
# List of useful tools and scripts for maintenance Synapse database:
|
||||
|
||||
## [Purge Remote Media API](../../admin_api/media_admin_api.md#purge-remote-media-api)
|
||||
The purge remote media API allows server admins to purge old cached remote media.
|
||||
|
||||
#### Purge local media
|
||||
|
||||
There is no purge API for local media because you may be the only one with a copy. If you are sure you want to delete local media you could use something like the following to delete media that hasn't been accessed in a while.
|
||||
|
||||
```
|
||||
find /path/to/synapse/media_store/local_content -atime +365 -delete
|
||||
find /path/to/synapse/media_store/local_thumbnails -atime +365 -delete
|
||||
```
|
||||
|
||||
This will delete media that hasn't been accessed in 365 days.
|
||||
|
||||
**Warning, check noatime flag**: You also have to double-check that the filesystem where synapse's media store don't have [noatime flag](https://unix.stackexchange.com/questions/219015/how-to-disable-access-time-settings-in-debian-linux/219017#219017). Check it with `mount`, `noatime` is something that is usually enabled by default to reduce read-write operations in the filesystem for a feature is not so demanded.
|
||||
|
||||
## [Purge History API](../../admin_api/purge_history_api.md)
|
||||
The purge history API allows server admins to purge historic events from their database, reclaiming disk space.
|
||||
|
||||
## [synapse_janitor.sql](https://github.com/xwiki-labs/synapse_scripts)
|
||||
|
||||
- this project is [unmantained and dangerous](https://github.com/xwiki-labs/synapse_scripts#unmaintained-and-dangerous)
|
||||
- USE WITH CAUTION. It may cause database corruption (see https://github.com/matrix-org/synapse/issues/7305 for example).
|
||||
- ["Our team hasn't used any of these scripts for some time (possibly years) (...) if anyone wants to volunteer to maintain this repo I'd be happy to transfer ownership.](https://github.com/xwiki-labs/synapse_scripts/pull/12#issuecomment-617275345)
|
||||
|
||||
Cleans a synapse Postgres database of deleted messages and abandoned rooms.
|
||||
|
||||
## [synapse-compress-state](https://github.com/matrix-org/rust-synapse-compress-state)
|
||||
Tool for compressing (deduplicating) `state_groups_state` table.
|
||||
|
||||
## [SQL for analyzing Synapse PostgreSQL database stats](https://github.com/matrix-org/synapse/wiki/SQL-for-analyzing-Synapse-PostgreSQL-database-stats)
|
||||
Some easy SQL that reports useful stat about Matrix Synapse database.
|
||||
25
docs/usage/administration/state_groups.md
Normal file
25
docs/usage/administration/state_groups.md
Normal file
@ -0,0 +1,25 @@
|
||||
# How do State Groups work?
|
||||
|
||||
As a general rule, I encourage people who want to understand the deepest darkest secrets of the database schema to drop by #synapse-dev:matrix.org and ask questions.
|
||||
|
||||
However, one question that comes up frequently is that of how "state groups" work, and why the `state_groups_state` table gets so big, so here's an attempt to answer that question.
|
||||
|
||||
We need to be able to relatively quickly calculate the state of a room at any point in that room's history. In other words, we need to know the state of the room at each event in that room. This is done as follows:
|
||||
|
||||
A sequence of events where the state is the same are grouped together into a `state_group`; the mapping is recorded in `event_to_state_groups`. (Technically speaking, since a state event usually changes the state in the room, we are recording the state of the room *after* the given event id: which is to say, to a handwavey simplification, the first event in a state group is normally a state event, and others in the same state group are normally non-state-events.)
|
||||
|
||||
`state_groups` records, for each state group, the id of the room that we're looking at, and also the id of the first event in that group. (I'm not sure if that event id is used much in practice.)
|
||||
|
||||
Now, if we stored all the room state for each `state_group`, that would be a huge amount of data. Instead, for each state group, we normally store the difference between the state in that group and some other state group, and only occasionally (every 100 state changes or so) record the full state.
|
||||
|
||||
So, most state groups have an entry in `state_group_edges` (don't ask me why it's not a column in `state_groups`) which records the previous state group in the room, and `state_groups_state` records the differences in state since that previous state group.
|
||||
|
||||
A full state group just records the event id for each piece of state in the room at that point.
|
||||
|
||||
## Known bugs with state groups
|
||||
|
||||
There are various reasons that we can end up creating many more state groups than we need: see https://github.com/matrix-org/synapse/issues/3364 for more details.
|
||||
|
||||
## Compression tool
|
||||
|
||||
There is a tool at https://github.com/matrix-org/rust-synapse-compress-state which can compress the `state_groups_state` on a room by-room basis (essentially, it reduces the number of "full" state groups). This can result in dramatic reductions of the storage used.
|
||||
@ -0,0 +1,72 @@
|
||||
## Understanding Synapse through Grafana graphs
|
||||
|
||||
It is possible monitor much of the internal state of Synapse using [Prometheus](https://prometheus.io) metrics and [Grafana](https://grafana.com/). A guide for configuring Synapse to provide metrics is available [here](../../metrics-howto.md) and information on setting up Grafana is [here](https://github.com/matrix-org/synapse/tree/master/contrib/grafana). In this setup, Prometheus will periodically scrape the information Synapse provides and store a record of it over time. Grafana is then used as an interface to query and present this information through a series of pretty graphs.
|
||||
|
||||
Once you have grafana set up, and assuming you're using [our grafana dashboard template](https://github.com/matrix-org/synapse/blob/master/contrib/grafana/synapse.json), look for the following graphs when debugging a slow/overloaded Synapse:
|
||||
|
||||
## Message Event Send Time
|
||||
|
||||

|
||||
|
||||
This, along with the CPU and Memory graphs, is a good way to check the general health of your Synapse instance. It represents how long it takes for a user on your homeserver to send a message.
|
||||
|
||||
## Transaction Count and Transaction Duration
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
These graphs show the database transactions that are occurring the most frequently, as well as those are that are taking the most amount of time to execute.
|
||||
|
||||

|
||||
|
||||
In the first graph, we can see obvious spikes corresponding to lots of `get_user_by_id` transactions. This would be useful information to figure out which part of the Synapse codebase is potentially creating a heavy load on the system. However, be sure to cross-reference this with Transaction Duration, which states that `get_users_by_id` is actually a very quick database transaction and isn't causing as much load as others, like `persist_events`:
|
||||
|
||||
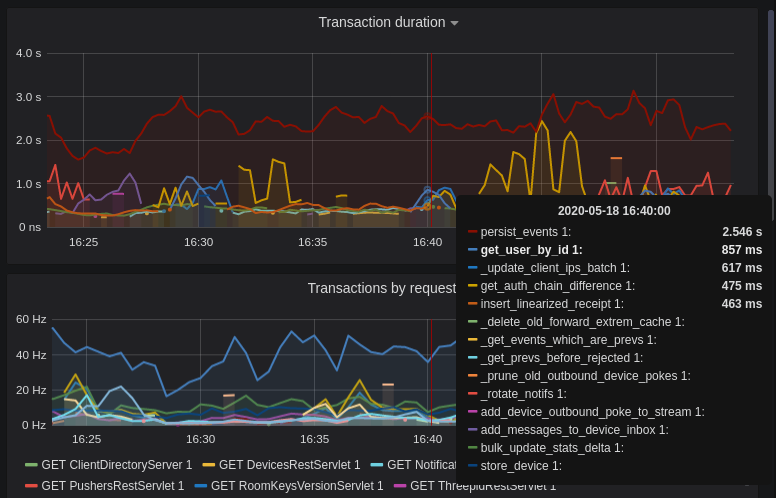
|
||||
|
||||
Still, it's probably worth investigating why we're getting users from the database that often, and whether it's possible to reduce the amount of queries we make by adjusting our cache factor(s).
|
||||
|
||||
The `persist_events` transaction is responsible for saving new room events to the Synapse database, so can often show a high transaction duration.
|
||||
|
||||
## Federation
|
||||
|
||||
The charts in the "Federation" section show information about incoming and outgoing federation requests. Federation data can be divided into two basic types:
|
||||
|
||||
- PDU (Persistent Data Unit) - room events: messages, state events (join/leave), etc. These are permanently stored in the database.
|
||||
- EDU (Ephemeral Data Unit) - other data, which need not be stored permanently, such as read receipts, typing notifications.
|
||||
|
||||
The "Outgoing EDUs by type" chart shows the EDUs within outgoing federation requests by type: `m.device_list_update`, `m.direct_to_device`, `m.presence`, `m.receipt`, `m.typing`.
|
||||
|
||||
If you see a large number of `m.presence` EDUs and are having trouble with too much CPU load, you can disable `presence` in the Synapse config. See also [#3971](https://github.com/matrix-org/synapse/issues/3971).
|
||||
|
||||
## Caches
|
||||
|
||||
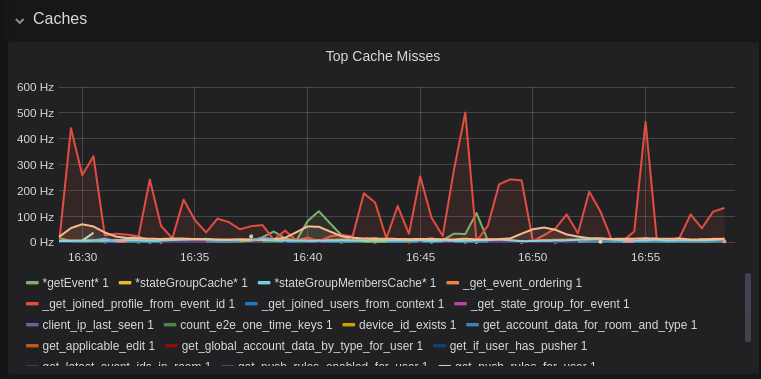
|
||||
|
||||
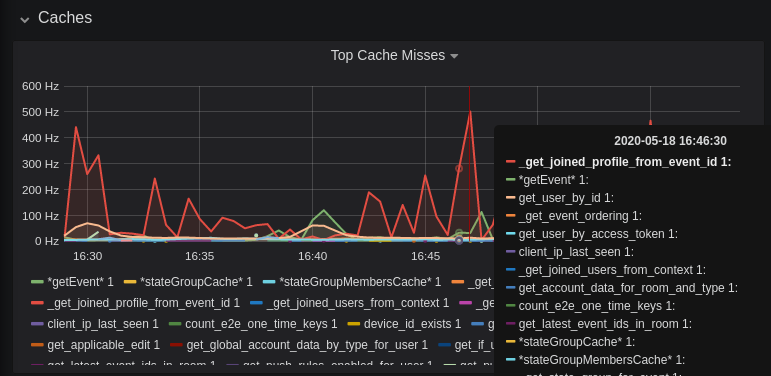
|
||||
|
||||
This is quite a useful graph. It shows how many times Synapse attempts to retrieve a piece of data from a cache which the cache did not contain, thus resulting in a call to the database. We can see here that the `_get_joined_profile_from_event_id` cache is being requested a lot, and often the data we're after is not cached.
|
||||
|
||||
Cross-referencing this with the Eviction Rate graph, which shows that entries are being evicted from `_get_joined_profile_from_event_id` quite often:
|
||||
|
||||

|
||||
|
||||
we should probably consider raising the size of that cache by raising its cache factor (a multiplier value for the size of an individual cache). Information on doing so is available [here](https://github.com/matrix-org/synapse/blob/ee421e524478c1ad8d43741c27379499c2f6135c/docs/sample_config.yaml#L608-L642) (note that the configuration of individual cache factors through the configuration file is available in Synapse v1.14.0+, whereas doing so through environment variables has been supported for a very long time). Note that this will increase Synapse's overall memory usage.
|
||||
|
||||
## Forward Extremities
|
||||
|
||||

|
||||
|
||||
Forward extremities are the leaf events at the end of a DAG in a room, aka events that have no children. The more exist in a room, the more [state resolution](https://matrix.org/docs/spec/server_server/r0.1.3#room-state-resolution) that Synapse needs to perform (hint: it's an expensive operation). While Synapse has code to prevent too many of these existing at one time in a room, bugs can sometimes make them crop up again.
|
||||
|
||||
If a room has >10 forward extremities, it's worth checking which room is the culprit and potentially removing them using the SQL queries mentioned in [#1760](https://github.com/matrix-org/synapse/issues/1760).
|
||||
|
||||
## Garbage Collection
|
||||
|
||||

|
||||
|
||||
Large spikes in garbage collection times (bigger than shown here, I'm talking in the multiple seconds range), can cause lots of problems in Synapse performance. It's more an indicator of problems, and a symptom of other problems though, so check other graphs for what might be causing it.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
If you're still having performance problems with your Synapse instance and you've tried everything you can, it may just be a lack of system resources. Consider adding more CPU and RAM, and make use of [worker mode](../../workers.md) to make use of multiple CPU cores / multiple machines for your homeserver.
|
||||
156
docs/usage/administration/useful_sql_for_admins.md
Normal file
156
docs/usage/administration/useful_sql_for_admins.md
Normal file
@ -0,0 +1,156 @@
|
||||
## Some useful SQL queries for Synapse Admins
|
||||
|
||||
## Size of full matrix db
|
||||
`SELECT pg_size_pretty( pg_database_size( 'matrix' ) );`
|
||||
### Result example:
|
||||
```
|
||||
pg_size_pretty
|
||||
----------------
|
||||
6420 MB
|
||||
(1 row)
|
||||
```
|
||||
## Show top 20 larger rooms by state events count
|
||||
```sql
|
||||
SELECT r.name, s.room_id, s.current_state_events
|
||||
FROM room_stats_current s
|
||||
LEFT JOIN room_stats_state r USING (room_id)
|
||||
ORDER BY current_state_events DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
and by state_group_events count:
|
||||
```sql
|
||||
SELECT rss.name, s.room_id, count(s.room_id) FROM state_groups_state s
|
||||
LEFT JOIN room_stats_state rss USING (room_id)
|
||||
GROUP BY s.room_id, rss.name
|
||||
ORDER BY count(s.room_id) DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
plus same, but with join removed for performance reasons:
|
||||
```sql
|
||||
SELECT s.room_id, count(s.room_id) FROM state_groups_state s
|
||||
GROUP BY s.room_id
|
||||
ORDER BY count(s.room_id) DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
## Show top 20 larger tables by row count
|
||||
```sql
|
||||
SELECT relname, n_live_tup as rows
|
||||
FROM pg_stat_user_tables
|
||||
ORDER BY n_live_tup DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
This query is quick, but may be very approximate, for exact number of rows use `SELECT COUNT(*) FROM <table_name>`.
|
||||
### Result example:
|
||||
```
|
||||
state_groups_state - 161687170
|
||||
event_auth - 8584785
|
||||
event_edges - 6995633
|
||||
event_json - 6585916
|
||||
event_reference_hashes - 6580990
|
||||
events - 6578879
|
||||
received_transactions - 5713989
|
||||
event_to_state_groups - 4873377
|
||||
stream_ordering_to_exterm - 4136285
|
||||
current_state_delta_stream - 3770972
|
||||
event_search - 3670521
|
||||
state_events - 2845082
|
||||
room_memberships - 2785854
|
||||
cache_invalidation_stream - 2448218
|
||||
state_groups - 1255467
|
||||
state_group_edges - 1229849
|
||||
current_state_events - 1222905
|
||||
users_in_public_rooms - 364059
|
||||
device_lists_stream - 326903
|
||||
user_directory_search - 316433
|
||||
```
|
||||
|
||||
## Show top 20 rooms by new events count in last 1 day:
|
||||
```sql
|
||||
SELECT e.room_id, r.name, COUNT(e.event_id) cnt FROM events e
|
||||
LEFT JOIN room_stats_state r USING (room_id)
|
||||
WHERE e.origin_server_ts >= DATE_PART('epoch', NOW() - INTERVAL '1 day') * 1000 GROUP BY e.room_id, r.name ORDER BY cnt DESC LIMIT 20;
|
||||
```
|
||||
|
||||
## Show top 20 users on homeserver by sent events (messages) at last month:
|
||||
```sql
|
||||
SELECT user_id, SUM(total_events)
|
||||
FROM user_stats_historical
|
||||
WHERE TO_TIMESTAMP(end_ts/1000) AT TIME ZONE 'UTC' > date_trunc('day', now() - interval '1 month')
|
||||
GROUP BY user_id
|
||||
ORDER BY SUM(total_events) DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
## Show last 100 messages from needed user, with room names:
|
||||
```sql
|
||||
SELECT e.room_id, r.name, e.event_id, e.type, e.content, j.json FROM events e
|
||||
LEFT JOIN event_json j USING (room_id)
|
||||
LEFT JOIN room_stats_state r USING (room_id)
|
||||
WHERE sender = '@LOGIN:example.com'
|
||||
AND e.type = 'm.room.message'
|
||||
ORDER BY stream_ordering DESC
|
||||
LIMIT 100;
|
||||
```
|
||||
|
||||
## Show top 20 larger tables by storage size
|
||||
```sql
|
||||
SELECT nspname || '.' || relname AS "relation",
|
||||
pg_size_pretty(pg_total_relation_size(C.oid)) AS "total_size"
|
||||
FROM pg_class C
|
||||
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
|
||||
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
|
||||
AND C.relkind <> 'i'
|
||||
AND nspname !~ '^pg_toast'
|
||||
ORDER BY pg_total_relation_size(C.oid) DESC
|
||||
LIMIT 20;
|
||||
```
|
||||
### Result example:
|
||||
```
|
||||
public.state_groups_state - 27 GB
|
||||
public.event_json - 9855 MB
|
||||
public.events - 3675 MB
|
||||
public.event_edges - 3404 MB
|
||||
public.received_transactions - 2745 MB
|
||||
public.event_reference_hashes - 1864 MB
|
||||
public.event_auth - 1775 MB
|
||||
public.stream_ordering_to_exterm - 1663 MB
|
||||
public.event_search - 1370 MB
|
||||
public.room_memberships - 1050 MB
|
||||
public.event_to_state_groups - 948 MB
|
||||
public.current_state_delta_stream - 711 MB
|
||||
public.state_events - 611 MB
|
||||
public.presence_stream - 530 MB
|
||||
public.current_state_events - 525 MB
|
||||
public.cache_invalidation_stream - 466 MB
|
||||
public.receipts_linearized - 279 MB
|
||||
public.state_groups - 160 MB
|
||||
public.device_lists_remote_cache - 124 MB
|
||||
public.state_group_edges - 122 MB
|
||||
```
|
||||
|
||||
## Show rooms with names, sorted by events in this rooms
|
||||
`echo "select event_json.room_id,room_stats_state.name from event_json,room_stats_state where room_stats_state.room_id=event_json.room_id" | psql synapse | sort | uniq -c | sort -n`
|
||||
### Result example:
|
||||
```
|
||||
9459 !FPUfgzXYWTKgIrwKxW:matrix.org | This Week in Matrix
|
||||
9459 !FPUfgzXYWTKgIrwKxW:matrix.org | This Week in Matrix (TWIM)
|
||||
17799 !iDIOImbmXxwNngznsa:matrix.org | Linux in Russian
|
||||
18739 !GnEEPYXUhoaHbkFBNX:matrix.org | Riot Android
|
||||
23373 !QtykxKocfZaZOUrTwp:matrix.org | Matrix HQ
|
||||
39504 !gTQfWzbYncrtNrvEkB:matrix.org | ru.[matrix]
|
||||
43601 !iNmaIQExDMeqdITdHH:matrix.org | Riot
|
||||
43601 !iNmaIQExDMeqdITdHH:matrix.org | Riot Web/Desktop
|
||||
```
|
||||
|
||||
## Lookup room state info by list of room_id
|
||||
```sql
|
||||
SELECT rss.room_id, rss.name, rss.canonical_alias, rss.topic, rss.encryption, rsc.joined_members, rsc.local_users_in_room, rss.join_rules
|
||||
FROM room_stats_state rss
|
||||
LEFT JOIN room_stats_current rsc USING (room_id)
|
||||
WHERE room_id IN (WHERE room_id IN (
|
||||
'!OGEhHVWSdvArJzumhm:matrix.org',
|
||||
'!YTvKGNlinIzlkMTVRl:matrix.org'
|
||||
)
|
||||
```
|
||||
Loading…
Reference in New Issue
Block a user