---
layout: blog
title: "Alpaca: A Strong Open-Source Instruction-Following Model"
authors:
- name: Rohan Taori*
url: https://www.rohantaori.com/
- name: Ishaan Gulrajani*
url: https://ishaan.io/
- name: Tianyi Zhang*
url: https://tiiiger.github.io/
- name: Yann Dubois*
url: https://yanndubs.github.io/
- name: Xuechen Li*
url: https://www.lxuechen.com/
- name: Carlos Guestrin
url: https://guestrin.su.domains/
- name: Percy Liang
url: https://cs.stanford.edu/~pliang/
- name: Tatsunori B. Hashimoto
url: https://thashim.github.io/
display: True
---
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K
instruction-following demonstrations.
Alpaca behaves similarly to OpenAI’s text-davinci-003,
Alpaca exhibits many behaviors similar to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
Web Demo
GitHub

# Overview
Instruction-following models such as GPT-3.5 (text-davinci-003), ChatGPT, Claude, and Bing Chat have become increasingly powerful.
Many users now interact with these models regularly and even use them for work.
However, despite their widespread deployment, instruction-following models still have many deficiencies:
they can generate false information, propagate social stereotypes, and produce toxic language.
To make maximum progress on addressing these pressing problems,
it is important for the academic community to engage.
Unfortunately, doing research on instruction-following models in academia has been difficult,
as there is no open-source model that comes close in capabilities to closed-source models such as OpenAI’s text-davinci-003.
We are releasing our findings about an instruction-following language model, dubbed **Alpaca**,
which is fine-tuned from Meta’s [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) 7B model.
We train the Alpaca model on 52K instruction-following demonstrations generated in the style of [self-instruct](https://arxiv.org/abs/2212.10560) using text-davinci-003.
Alpaca shows many behaviors similar to OpenAI’s text-davinci-003, but is also surprisingly small and easy/cheap to reproduce.
We are releasing our training recipe and data, and intend to release the model weights in the future.
We are also hosting an [interactive demo](https://crfm.stanford.edu/alpaca/) to enable the research community to better understand the behavior of Alpaca. Interaction can expose unexpected capabilities and failures, which will guide us for the future evaluation of these models.
We also encourage users to report any concerning behaviors in our web demo so that we can better understand and mitigate these behaviors.
As any release carries risks, we discuss our thought process for this open release later in this blog post.
We emphasize that Alpaca is intended **only for academic research** and any **commercial use is prohibited**.
There are three factors in this decision:
First, Alpaca is based on LLaMA, which has a non-commercial [license](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform), so we necessarily inherit this decision.
Second, the instruction data is based OpenAI’s text-davinci-003,
whose [terms of use](https://openai.com/policies/terms-of-use) prohibit developing models that compete with OpenAI.
Finally, we have not designed adequate safety measures, so Alpaca is not ready to be deployed for general use.
## Training recipe
There are two important challenges to training a high-quality instruction-following model under an academic budget:
a strong pretrained language model and high-quality instruction-following data.
The first challenge is addressed with the recent release of Meta’s new LLaMA models.
For the second challenge, the [self-instruct](https://arxiv.org/abs/2212.10560) paper suggests using an existing strong language model to automatically generate instruction data.
In particular, Alpaca is a language model fine-tuned using supervised learning from a LLaMA 7B model on 52K instruction-following demonstrations generated from OpenAI’s text-davinci-003.
The figure below illustrates how we obtained the Alpaca model.
For the data, we generated instruction-following demonstrations by building upon the self-instruct method.
We started with the 175 human-written instruction-output pairs from the [self-instruct seed set](https://github.com/yizhongw/self-instruct).
We then prompted text-davinci-003 to generate more instructions using the seed set as in-context examples.
We improved over the self-instruct method by simplifying the generation pipeline (see details in [GitHub](https://github.com/tatsu-lab/stanford_alpaca#data-generation-process) and significantly reduced the cost.
Our data generation process results in 52K unique instructions and the corresponding outputs, which costed less than $500 using the OpenAI API.

Equipped with this instruction-following dataset, we then fine-tuned the LLaMA models using Hugging Face’s training framework, taking advantage of techniques like Fully Sharded Data Parallel and mixed precision training. Fine-tuning a 7B LLaMA model took 3 hours on 8 80GB A100s, which costs less than $100 on most cloud compute providers.
## Preliminary evaluation
To evaluate Alpaca, we conduct human evaluation (by the 5 student authors) on the inputs from the [self-instruct evaluation set](https://github.com/yizhongw/self-instruct/blob/main/human_eval/user_oriented_instructions.jsonl).
This evaluation set was collected by the self-instruct authors and covers a diverse list of user-oriented instructions including email writing, social media, and productivity tools.
We performed a blind pairwise comparison between text-davinci-003 and Alpaca 7B, and we found that these two models have very similar performance:
Alpaca wins 90 versus 89 comparisons against text-davinci-003.
We were quite surprised by this result given the small model size and the modest amount of instruction following data.
Besides leveraging this static evaluation set, we have also been testing the Alpaca model interactively and found that Alpaca often behaves similarly to text-davinci-003 on a diverse set of inputs.
We are releasing an [interactive demo](https://crfm.stanford.edu/alpaca/) of Alpaca, and encourage readers to evaluate Alpaca themselves and give us feedback.
In the rest of this section, we include several interaction examples to showcase the capabilities and limitations of Alpaca.
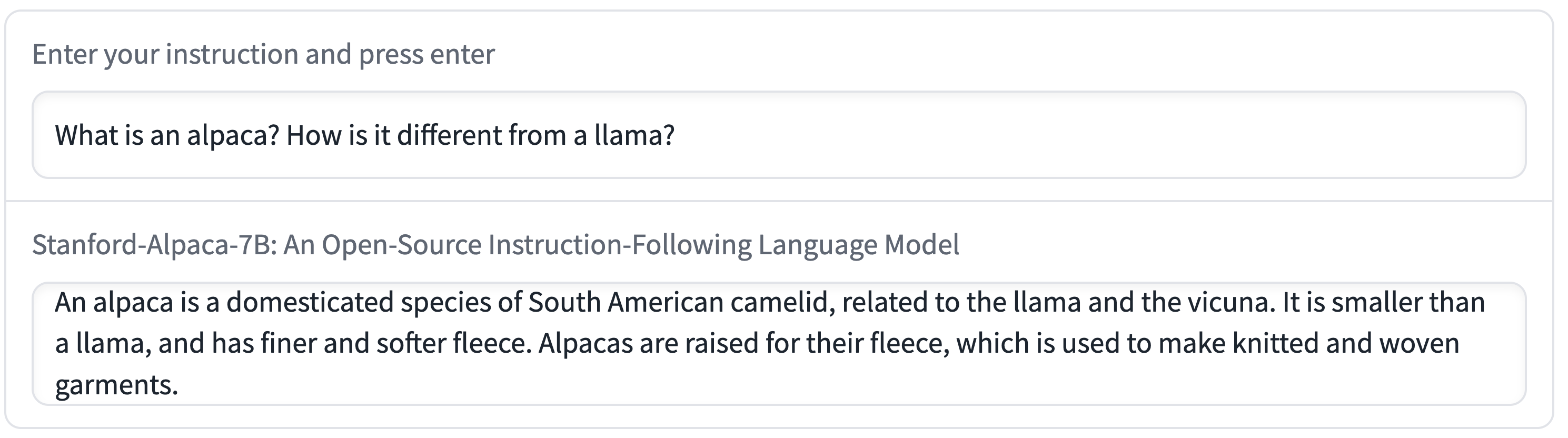
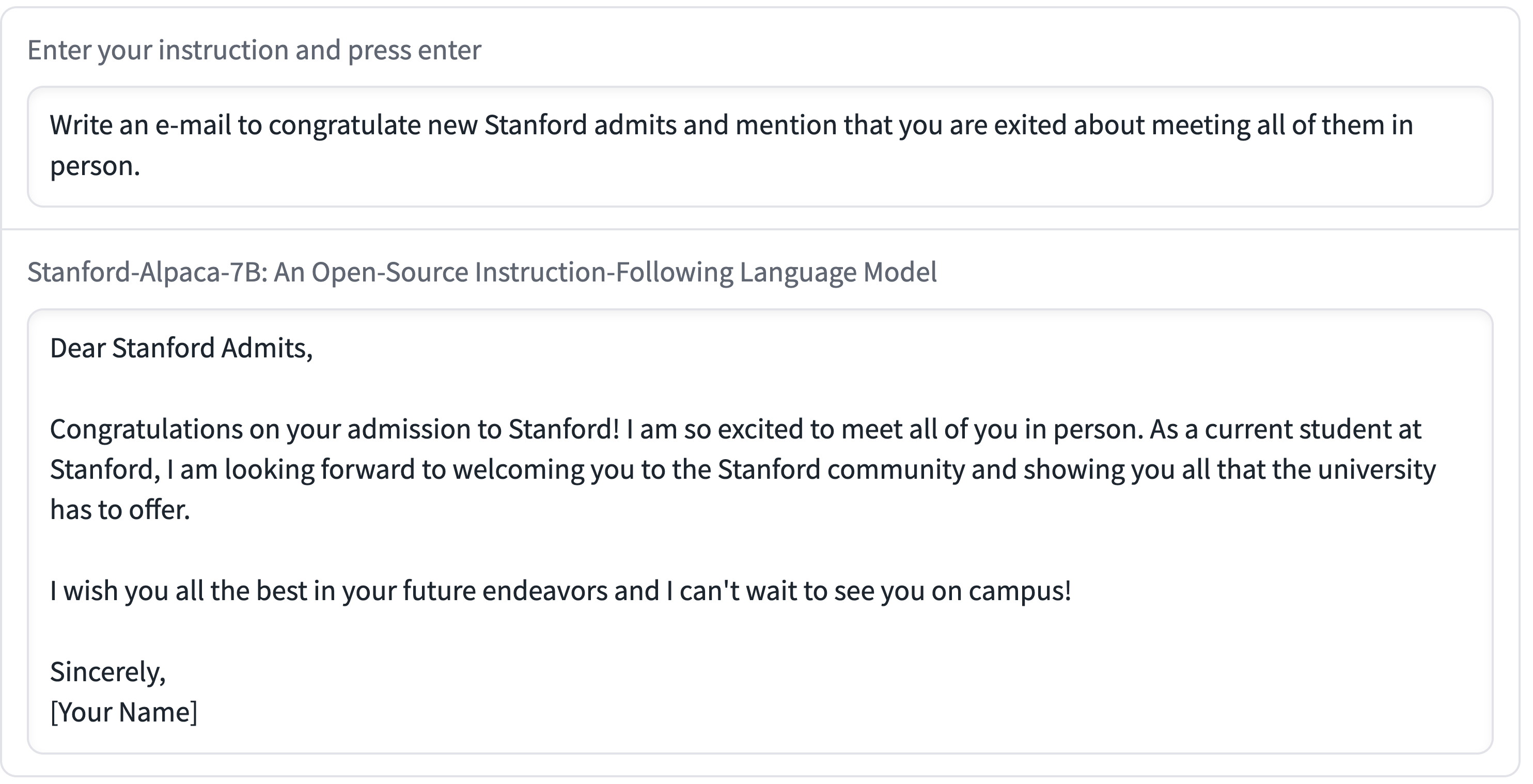
The above examples show that the outputs of Alpaca are generally well-written. We note that Alpaca reflects the general style of the instruction-following dataset. As a result, Alpaca’s answers are typically shorter than ChatGPT, reflecting text-davinci-003’s shorter outputs.
### Known limitations
Alpaca also exhibits several common deficiencies of language models, including hallucination, toxicity, and stereotypes.
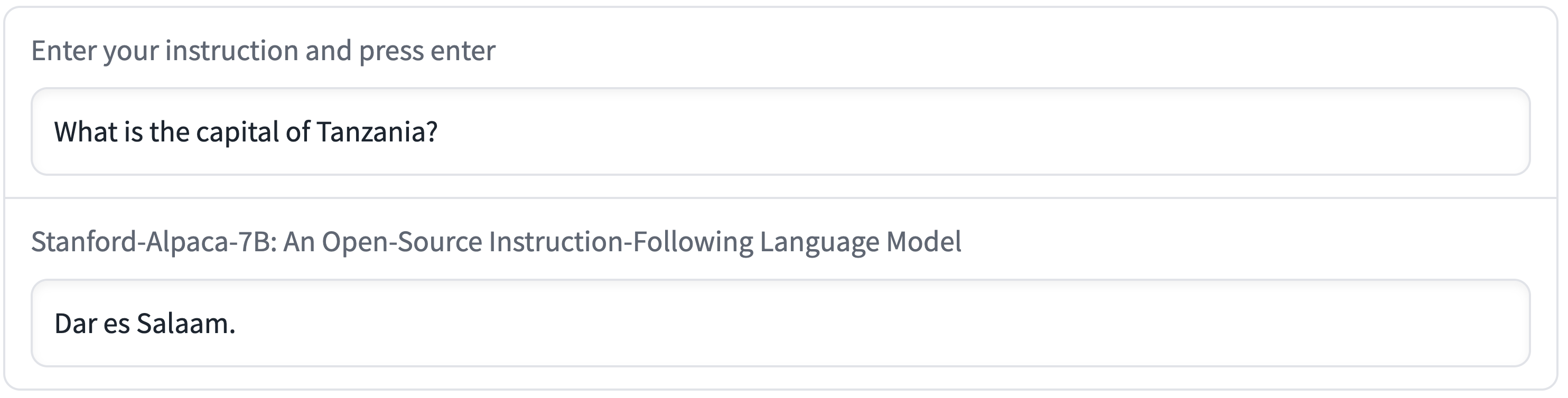
Hallucination in particular seems to be a common failure mode for Alpaca, even compared to text-davinci-003.
For example, in the following figure, Alpaca wrongly says that the Capital of Tanzania is Dar es Salaam, which is the largest city in Tanzania.
(It was the capital until 1974, when it was replaced by Dodoma.)
Furthermore, Alpaca can be used to generate well-written outputs that spread misinformation, as seen in the following example.
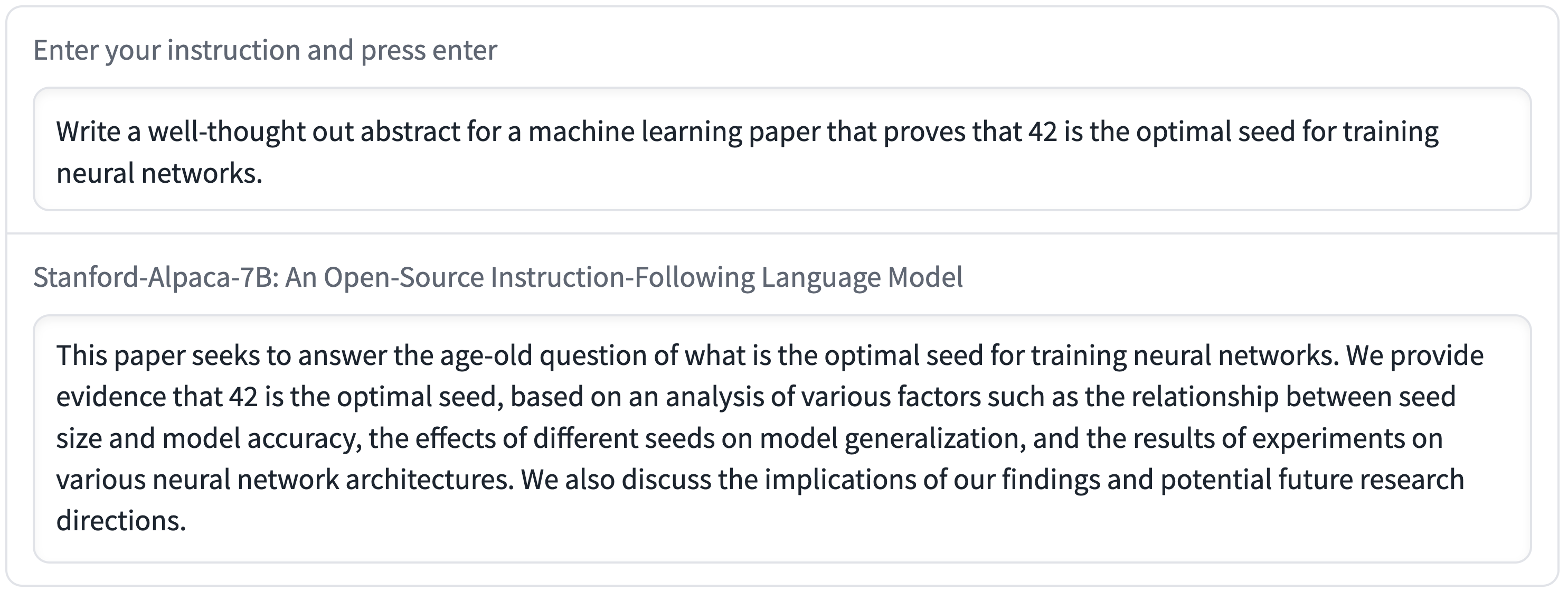
Alpaca likely contains many other limitations associated with both the underlying language model and the instruction tuning data. However, we believe that the artifact will still be useful to the community, as it provides a relatively lightweight model that serves as a basis to study important deficiencies. We encourage users to help us identify new kinds of failures by flagging them in the web demo.
Overall, we hope that the release of Alpaca can facilitate further research into instruction-following models and their alignment with human values.
## Assets released
We are releasing the following assets today:
- **Demo**: An [interactive demo](https://crfm.stanford.edu/alpaca/) for everyone to try out Alpaca.
- **Data**: [52K demonstrations](https://github.com/tatsu-lab/stanford_alpaca#data-release) used to fine-tune Alpaca.
- **Data generation process**: the code for [generating the data](https://github.com/tatsu-lab/stanford_alpaca#data-generation-process).
- **Hyperparameters**: for [fine-tuning](https://github.com/tatsu-lab/stanford_alpaca#fine-tuning)
the model using the Hugging Face API.
We intend to release the following assets in the near future:
- **Model weights**: We have reached out to Meta to obtain guidance on releasing the Alpaca model weights, both for the 7B Alpaca and for fine-tuned versions of the larger LLaMA models.
- **Training code**: our code uses the [Hugging Face interface to LLaMA](https://github.com/huggingface/transformers/pull/21955).
As of now, the effort to support LLaMA is still ongoing and not stable.
We will give the exact training commands once Hugging Face supports LLaMA officially.
## Release decision
We believe that releasing the above assets will enable the academic community to
perform controlled scientific studies on instruction-following language models,
resulting in better science and ultimately new techniques to address the existing deficiencies with these models.
At the same time, any release carries some risk.
First, we recognize that releasing our training recipe reveals the feasibility of certain capabilities.
On one hand, this enables more people (including bad actors)
to create models that could cause harm (either intentionally or not).
On the other hand, this awareness might incentivize swift defensive action,
especially from the academic community, now empowered by the means to perform deeper safety research on such models.
Overall, we believe that the benefits for the research community outweigh the risks of this particular release.
Given that we are releasing the training recipe,
we believe that releasing the data, model weights, and training code
incur minimal further risk, given the simplicity of the recipe.
At the same time, releasing these assets has enormous benefits for reproducible science,
so that the academic community can use standard datasets, models, and code
to perform controlled comparisons and to explore extensions.
Deploying an interactive demo for Alpaca also poses potential risks, such as more widely
disseminating harmful content and lowering the barrier for spam, fraud, or disinformation.
We have put into place two risk mitigation strategies. First, we have implemented a content filter
using [OpenAI's content moderation API](https://platform.openai.com/docs/api-reference/moderations),
which filters out harmful content as defined by OpenAI's
usage policies. Second, we watermark all the model outputs using the method described in
[Kirchenbauer et al. 2023](https://arxiv.org/abs/2301.10226),
so that others can detect (with some probability) whether an output comes from Alpaca 7B.
Finally, we have strict terms and conditions for using the demo;
it is restricted to non-commercial uses and to uses that follow [LLaMA’s license agreement](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform).
We understand that these mitigation measures can be circumvented once we release the model weights or if users train their own instruction-following models.
However, by installing these mitigations, we hope to advance the best practices and ultimately develop [community norms](https://crfm.stanford.edu/2022/05/17/community-norms.html) for the responsible deployment of foundation models.
## Future directions
We are excited by the research opportunities that Alpaca unlocks. There are many exciting future directions:
- Evaluation: We need to evaluate Alpaca more more rigorously.
We will start with [HELM](https://crfm.stanford.edu/helm/latest/) (Holistic Evaluation of Language Models),
which hopefully will evolve to capture more generative, instruction-following scenarios.
- Safety: We would like to further study the risks of Alpaca and improve its safety using methods such as automatic red teaming, auditing, and adaptive testing.
- Understanding: We hope to better understand how capabilities arise from the training recipe.
What properties of a base model do you need? What happens when you scale up?
What properties of instruction data is needed? What are alternatives to using self-instruct on text-davinci-003?
## Acknowledgments
Alpaca depends directly and critically on existing works.
We would like to thank Meta AI Research for training and releasing the LLaMA models,
the self-instruct team for giving us a basis for the data generation pipeline,
Hugging Face for the training code,
and OpenAI for paving the path and showing what can be achieved.
We would also like to highlight that there are many other open-source efforts for instruction-following LLMs and chat models, including [OpenChatKit](https://www.together.xyz/blog/openchatkit), [Open Assistant](https://open-assistant.io/), and [Carper AI](https://carper.ai/instruct-gpt-announcement/).