| evaluator | ||
| sh | ||
| tokenizer | ||
| _utils.py | ||
| CODE_OF_CONDUCT.md | ||
| CODEOWNERS | ||
| codet5.gif | ||
| CodeT5_model_card.pdf | ||
| CodeT5.png | ||
| configs.py | ||
| LICENSE.txt | ||
| models.py | ||
| README.md | ||
| run_clone.py | ||
| run_gen.py | ||
| SECURITY.md | ||
| utils.py | ||
{kind=link}
{kind=link}
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation
This is the official PyTorch implementation for the following EMNLP 2021 paper from Salesforce Research:
Authors: Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi
Updates
Oct 25, 2021
We release a CodeT5-base fine-tuned checkpoint (Salesforce/codet5-base-multi-sum) for multi-lingual code summarzation. Below is how to use this model:
from transformers import RobertaTokenizer, T5ForConditionalGeneration
if __name__ == '__main__':
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-base')
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-base-multi-sum')
text = """def svg_to_image(string, size=None):
if isinstance(string, unicode):
string = string.encode('utf-8')
renderer = QtSvg.QSvgRenderer(QtCore.QByteArray(string))
if not renderer.isValid():
raise ValueError('Invalid SVG data.')
if size is None:
size = renderer.defaultSize()
image = QtGui.QImage(size, QtGui.QImage.Format_ARGB32)
painter = QtGui.QPainter(image)
renderer.render(painter)
return image"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=20)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
# this prints: "Convert a SVG string to a QImage."
It significantly outperforms previous methods on code summarization in the CodeXGLUE benchmark:
| Model | Ruby | Javascript | Go | Python | Java | PHP | Overall |
|---|---|---|---|---|---|---|---|
| Seq2Seq | 9.64 | 10.21 | 13.98 | 15.93 | 15.09 | 21.08 | 14.32 |
| Transformer | 11.18 | 11.59 | 16.38 | 15.81 | 16.26 | 22.12 | 15.56 |
| RoBERTa | 11.17 | 11.90 | 17.72 | 18.14 | 16.47 | 24.02 | 16.57 |
| CodeBERT | 12.16 | 14.90 | 18.07 | 19.06 | 17.65 | 25.16 | 17.83 |
| PLBART | 14.11 | 15.56 | 18.91 | 19.30 | 18.45 | 23.58 | 18.32 |
| CodeT5-base-multi-sum | 15.24 | 16.18 | 19.95 | 20.42 | 20.26 | 26.10 | 19.69 |
Oct 18, 2021
We add a model card for CodeT5! Please reach out if you have any questions about it.
Sep 24, 2021
CodeT5 is now in hugginface!
You can simply load the model (CodeT5-small and CodeT5-base) and do the inference:
from transformers import RobertaTokenizer, T5ForConditionalGeneration
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-base')
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-base')
text = "def greet(user): print(f'hello <extra_id_0>!')"
input_ids = tokenizer(text, return_tensors="pt").input_ids
# simply generate one code span
generated_ids = model.generate(input_ids, max_length=8)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
# this prints "{user.username}"
Introduction
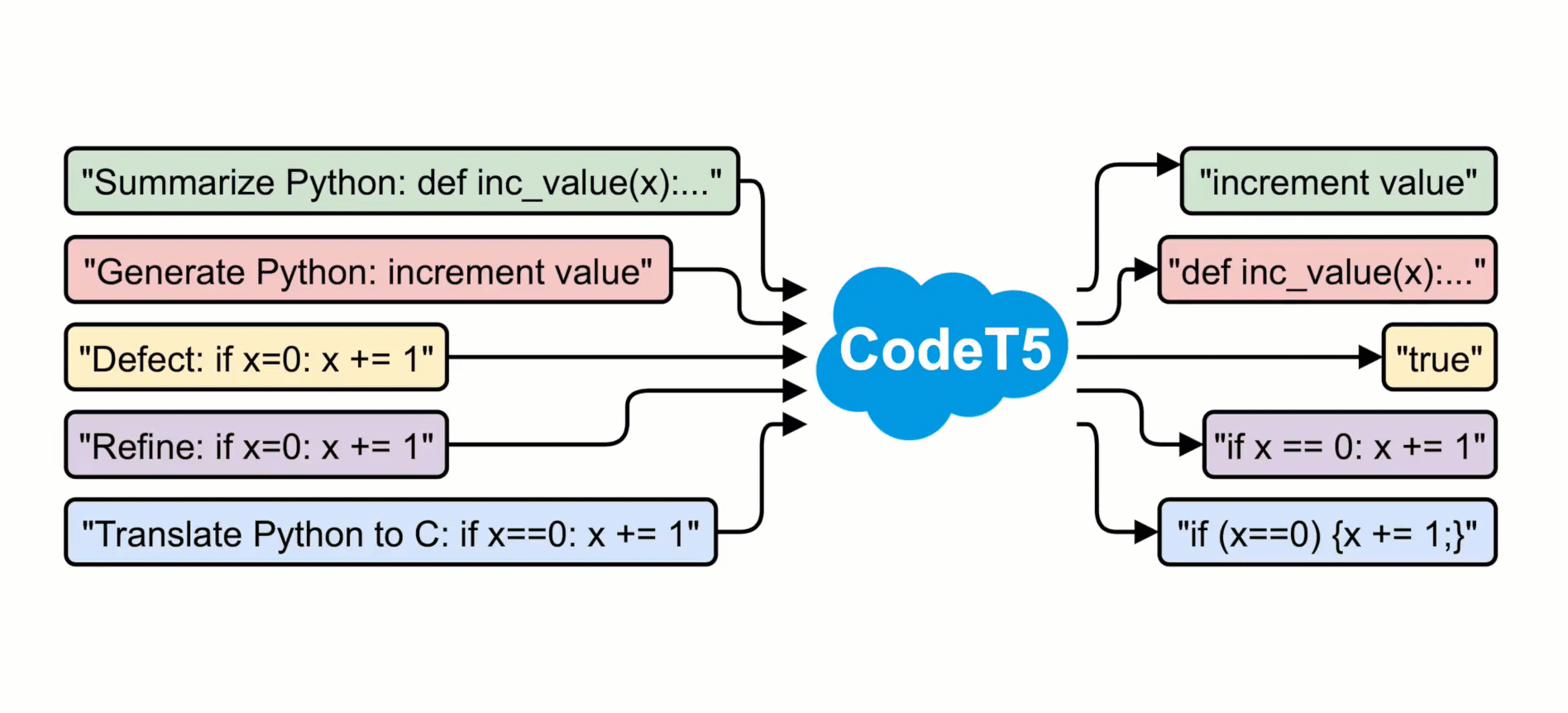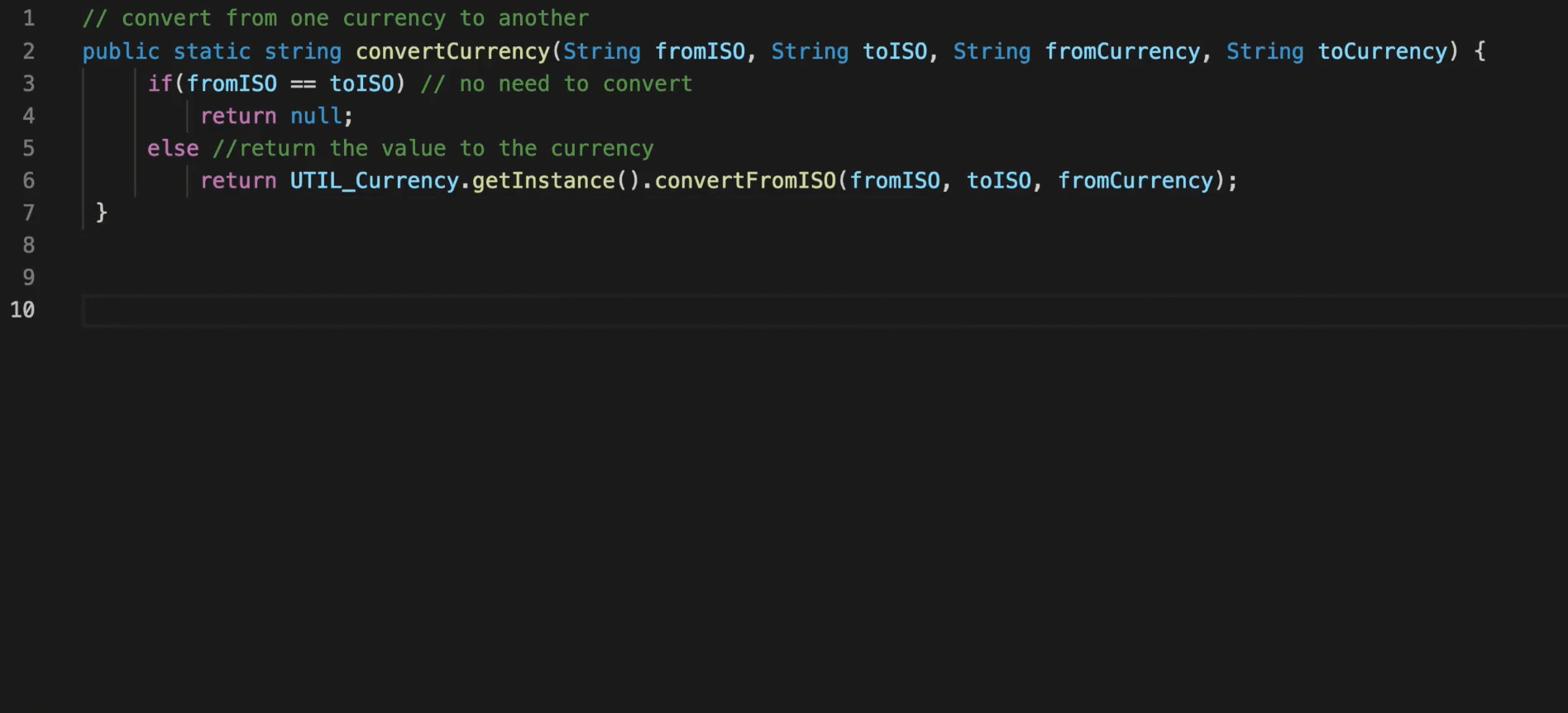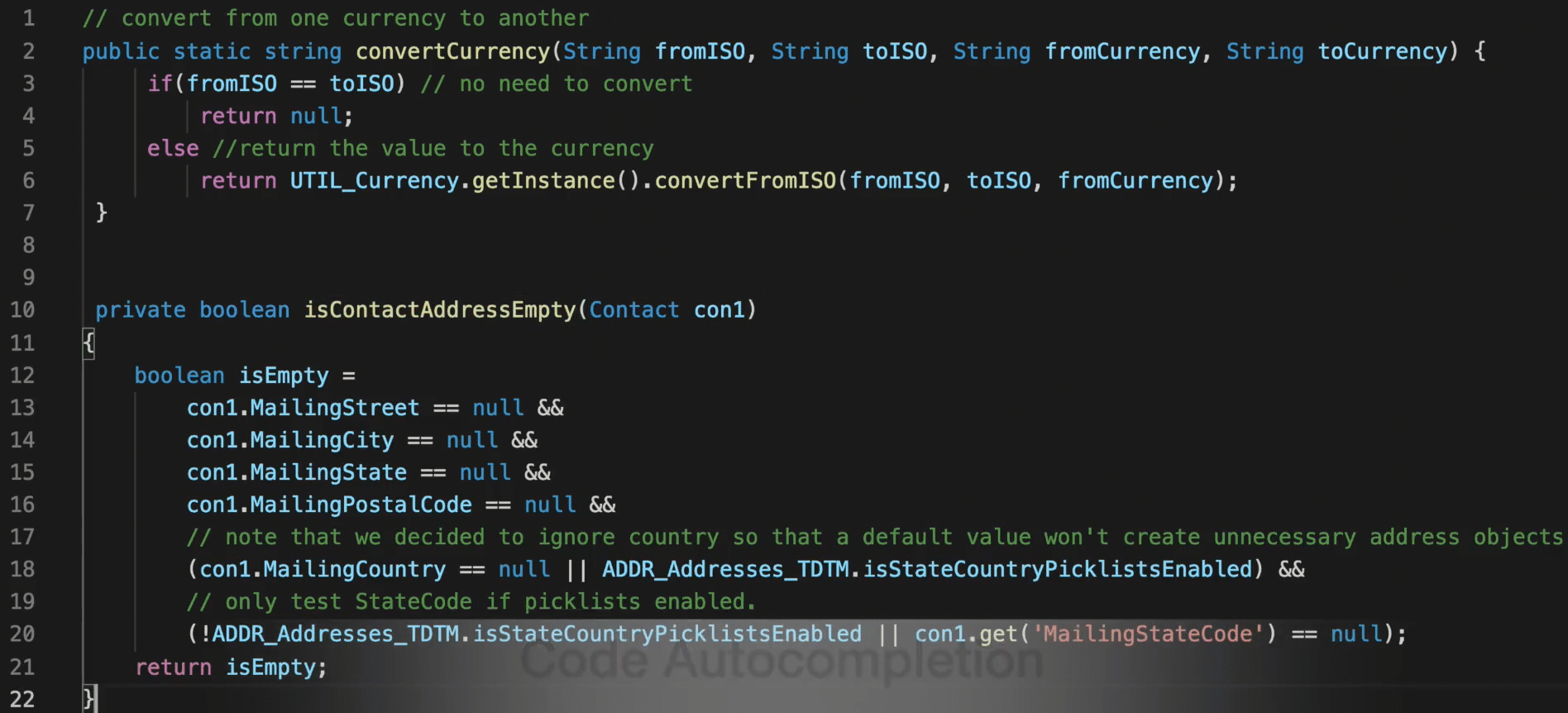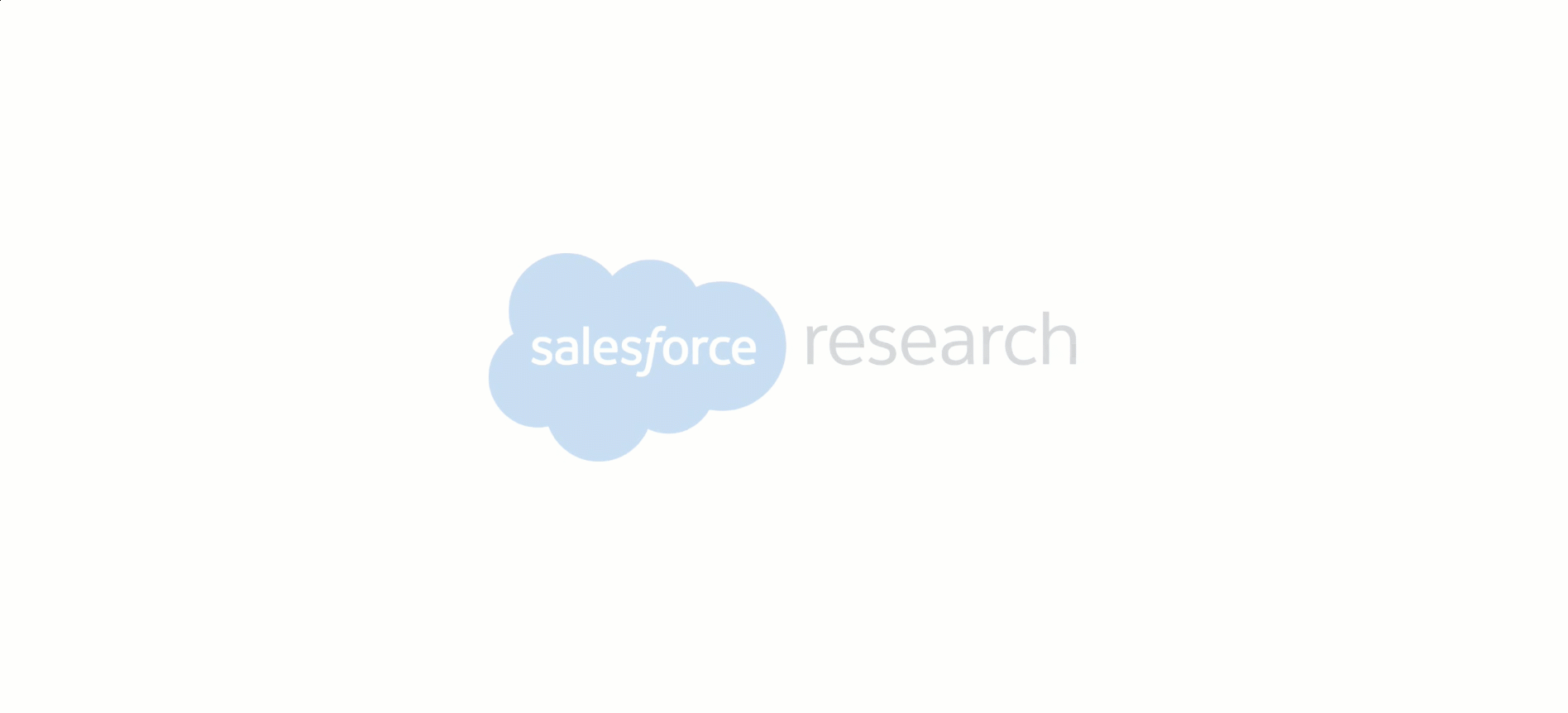
This repo provides the code for reproducing the experiments in CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. CodeT5 is a new pre-trained encoder-decoder model for programming languages, which is pre-trained on 8.35M functions in 8 programming languages (Python, Java, JavaScript, PHP, Ruby, Go, C, and C#). In total, it achieves state-of-the-art results on 14 sub-tasks in a code intelligence benchmark - CodeXGLUE.
Paper link: https://arxiv.org/abs/2109.00859
Blog link: https://blog.einstein.ai/codet5/
The code currently includes two pre-trained checkpoints (CodeT5-small and CodeT5-base) and scripts to fine-tine them on 4 generation tasks (code summarization, code generation, translation, and refinement) plus 2 understanding tasks (code defect detection and clone detection) in CodeXGLUE.
In practice, CodeT5 can be deployed as an AI-powered coding assistant to boost the productivity of software developers. At Salesforce, we build an AI coding assistant demo using CodeT5 as a VS Code plugin to provide three capabilities for Apex developers:
{kind=link}
- Text-to-code generation: generate code based on the natural language description.
- Code autocompletion: complete the whole function of code given the target function name.
- Code summarization: generate the summary of a function in natural language description.
Table of Contents
Citation
If you find this code to be useful for your research, please consider citing.
@inproceedings{
wang2021codet5,
title={CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
author={Yue Wang, Weishi Wang, Shafiq Joty, Steven C.H. Hoi},
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021},
year={2021},
}
License
The code is released under the BSD-3 License (see LICENSE.txt for details), but we also ask that users respect the following:
This software should not be used to promote or profit from:
violence, hate, and division,
environmental destruction,
abuse of human rights, or
the destruction of people's physical and mental health.
We encourage users of this software to tell us about the applications in which they are putting it to use by emailing codeT5@salesforce.com, and to use appropriate documentation when developing high-stakes applications of this model.
Dependency
- Pytorch 1.7.1
- tensorboard 2.4.1
- transformers 4.6.1
- tree-sitter 0.2.2
Download
- Pre-trained checkpoints & Fine-tuning data
- Fine-tuned checkpoints (TBA)
- Extra C/C# pre-training data (TBA)
Instructions to download:
pip install gsutil
gsutil -m cp -r "gs://sfr-codet5-data-research/data/" .
mkdir pretrained_models; cd pretrained_models
gsutil -m cp -r \
"gs://sfr-codet5-data-research/pretrained_models/codet5_small" \
"gs://sfr-codet5-data-research/pretrained_models/codet5_base" \
.
The repository structure will look like the following after the download:
├── CODE_OF_CONDUCT.md
├── README.md
├── SECURITY.md
├── codet5.gif
├── configs.py
├── models.py
├── run_clone.py
├── run_gen.py
├── utils.py
├── _utils.py
├── LICENSE.txt
├── data
│ ├── clone
│ ├── concode
│ ├── defect
│ ├── refine
│ │ ├── medium
│ │ └── small
│ ├── summarize
│ │ ├── go
│ │ ├── java
│ │ ├── javascript
│ │ ├── php
│ │ ├── python
│ │ └── ruby
│ └── translate
├── evaluator
│ ├── bleu.py
│ ├── smooth_bleu.py
│ └── CodeBLEU
├── pretrained_models
│ ├── codet5_base
│ └── codet5_small
├── sh
│ ├── exp_with_args.sh
│ ├── run_exp.py
│ ├── results
│ ├── saved_models
│ └── tensorboard
└── tokenizer
└── salesforce
├── codet5-merges.txt
└── codet5-vocab.json
Fine-tuning
Go to sh folder, set the WORKDIR in exp_with_args.sh to be your downloaded CodeT5 repository path.
You can use run_exp.py to run a broad set of experiments by simply passing the model_tag, task, and sub_task arguments.
In total, we support four models (i.e., ['roberta', 'codebert', 'codet5_small', 'codet5_base']) and six tasks (i.e., ['summarize', 'concode', 'translate', 'refine', 'defect', 'clone']).
For each task, we use the sub_task to specify which specific datasets to fine-tine on.
For example, if you want to run CodeT5-base model on the code summarization task for Ruby, you can simply run:
python run_exp.py --model_tag codet5_base --task summarize --sub_task ruby
Besides, you can specify:
model_dir: where to save fine-tuning checkpoints
res_dir: where to save the performance results
summary_dir: where to save the training curves
data_num: how many data instances to use, the default -1 is for using the full data
gpu: the index of the GPU to use in the cluster
You can also revise the suggested arguments here and refer to the argument flags in configs.py for the full available options.
The saved training curves in summary_dir can be visualized using tensorboard.
Get Involved
Please create a GitHub issue if you have any questions, suggestions, requests or bug-reports. We welcome PRs!